
Hadoop is a powerful open-source framework for storing and processing large datasets, making it essential for tackling the challenges of big data in today’s world.
Learning Hadoop opens doors to exciting career opportunities in data engineering, analytics, and machine learning.
Mastering this framework enables you to build robust data pipelines, analyze massive datasets, and gain valuable insights that can drive business decisions.
Finding the right Hadoop course on Udemy can be a daunting task, with so many options vying for your attention.
You want a course that’s comprehensive, engaging, and taught by experts who can guide you through the complexities of Hadoop and its ecosystem.
For the best Hadoop course overall on Udemy, we recommend The Ultimate Hands-On Hadoop: Tame your Big Data!.
This course stands out for its hands-on approach, practical projects, and comprehensive coverage of the Hadoop ecosystem.
You’ll learn how to set up a Hadoop sandbox locally, explore core components like HDFS and MapReduce, and gain hands-on experience analyzing real data using Pig Latin, Hive, and Spark.
The course also covers advanced topics like NoSQL databases, cluster management, and data streaming, making it a perfect choice for both beginners and those looking to deepen their Hadoop knowledge.
While The Ultimate Hands-On Hadoop: Tame your Big Data! is our top pick, there are other fantastic Hadoop courses on Udemy.
Keep reading to discover our full list of recommendations, tailored to different learning styles and career goals.
The Ultimate Hands-On Hadoop: Tame your Big Data!

The course starts by helping you set up the Hortonworks Data Platform (HDP) Sandbox on your PC, allowing you to run Hadoop locally.
You’ll learn about the history of Hadoop and get an overview of its ecosystem, covering buzzwords like HDFS, MapReduce, Pig, Hive, and Spark.
Once you have Hadoop up and running, the course dives into using its core components - HDFS for distributed storage and MapReduce for parallel processing.
You’ll import real movie ratings data into HDFS and write Python MapReduce jobs to analyze it.
The examples are hands-on and interactive, like finding the most popular movies by number of ratings.
Next, you’ll learn how to use Pig Latin scripting to perform complex analyses on your data without writing low-level Java code.
You’ll find the oldest highly-rated movies and identify the most popular bad movie using Pig scripts.
The course then covers Apache Spark in depth, using its RDD APIs, DataFrames, and machine learning library (MLLib) to build movie recommendation engines.
You’ll see how Spark improves upon MapReduce for efficient data processing.
The syllabus covers integrating Hadoop with relational databases like MySQL using Sqoop, as well as using NoSQL databases like HBase, Cassandra, and MongoDB to store and query your processed data.
You’ll get hands-on practice importing and exporting data between these systems and Hadoop.
For interactive querying, you’ll use tools like Drill, Phoenix and Presto to join data across multiple databases on the fly.
The course explains how these differ in their approaches.
You’ll also learn about cluster management with components like YARN, Tez, Mesos, ZooKeeper and Oozie.
Streaming data ingestion is covered using Kafka and Flume.
Finally, you’ll build real-world systems for tasks like analyzing web logs and providing movie recommendations.
The examples are practical, and you’ll be able to follow along on your own Hadoop sandbox as you learn each new technology hands-on.
The course covers a wide breadth of the Hadoop ecosystem in-depth, making it a great pick if you are interested in data engineering using Hadoop.
Learn Big Data: The Hadoop Ecosystem Masterclass

You’ll start by learning the fundamentals of big data and Hadoop, including what they are and why they’re important.
The course covers the key components of Hadoop, such as HDFS for storage and MapReduce for processing data.
You’ll get hands-on experience with installing Hadoop and using tools like the Hortonworks Sandbox and Ambari for managing Hadoop clusters.
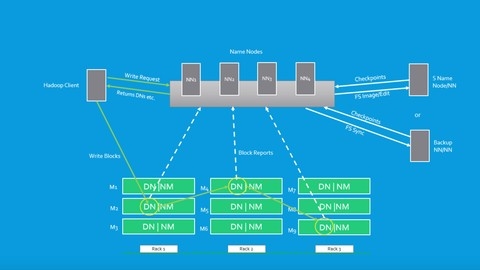
The course dives deep into core Hadoop components like HDFS, covering topics like DataNode communications, block placement, and the NameNode.
You’ll also learn about MapReduce and see a WordCount example.
The course covers essential tools in the Hadoop ecosystem.
You’ll learn Pig, a high-level language for data processing, and see demos of installing and using Pig.
Apache Spark, a powerful engine for big data processing, is covered in-depth, including RDDs, MLLib, and a WordCount example.
Hive, Hadoop’s data warehousing tool, is another key topic.
You’ll learn about Hive queries, partitioning, bucketing, and more.
The course also explores real-time processing with Kafka for messaging and Storm for stream processing.
For data storage, you’ll dive into HBase, Hadoop’s NoSQL database, learning about tables, writes, reads, and more.
You’ll also learn Phoenix, a SQL layer over HBase.
Security is crucial in big data, so the course covers Kerberos authentication, SPNEGO for web security, Knox for gateway security, and Ranger for authorization.
HDFS encryption is also covered.
Advanced topics include Yarn schedulers, query optimization strategies for Hive and Spark, and setting up high availability for the NameNode and databases.
Hive to ADVANCE Hive (Real time usage) :Hadoop querying tool

You’ll start by learning the basics of Hive, including its architecture, basic commands, and how it differs from SQL.
You’ll then dive into core Hive concepts like creating databases, defining table schemas, loading data into tables, and working with internal vs. external tables.
The course covers essential data manipulation techniques such as sorting, filtering with functions, conditional statements, and advanced functions like explode, lateral view, rank, and rlike.
A major focus is partitioning and bucketing data in Hive for efficient querying.
You’ll learn static and dynamic partitioning, altering partitioned tables, and bucketing concepts.
Table sampling and advanced commands like no_drop and offline are also covered.
The course provides in-depth coverage of joins in Hive, including inner, outer, and multi-table joins, as well as optimization techniques like map joins.
You’ll learn to create and use views, a powerful abstraction layer.
Advanced topics include indexing (compact and bitmap), user-defined functions (UDFs), setting table properties like skipping headers/footers and null formats, and understanding ACID/transactional properties of Hive tables.
You’ll explore Hive configurations, settings, and variables (hiveconf and hivevar), executing queries from bash, and running Unix/Hadoop commands within the Hive shell.
The course dives into different file formats like text, sequence, Avro, RC, ORC, and Parquet, helping you choose the right one.
Other key areas are custom input formatters, Hive modes, compression techniques, the Tez execution engine, loading XML data, and implementing slowly changing dimensions (SCDs) to capture updated data.
The course covers real-world use cases like word count, handling multiple tables on a single file, and interview questions.
You’ll gain hands-on experience with Hive installation and work through coding examples throughout.
Hadoop Developer In Real World

You will start by understanding what Big Data is and why we need tools like Hadoop to process it.
The course covers the core components of Hadoop like HDFS (Hadoop Distributed File System) and MapReduce, which form the foundation for working with large datasets.
You will learn how to write programs using MapReduce and solve real-world problems like finding mutual friends on Facebook.
The course also dives deep into Apache Pig, a high-level language for analyzing large datasets.
You will learn to load data, project datasets, solve complex problems, and perform operations like joins using Pig Latin.
Another key component covered is Apache Hive, a data warehousing tool that facilitates querying and analyzing data stored in Hadoop.
You will learn to create Hive tables, load data, write queries using HiveQL, and perform advanced operations like partitioning and bucketing.
It covers the architecture of Hadoop components like HDFS and YARN (Yet Another Resource Negotiator), as well as setting up Hadoop clusters and using cloud services like Amazon EMR.
You will also explore various file formats used in the Hadoop ecosystem, such as Avro, ORC, Parquet, and RCFile.
The course teaches you how to work with these formats, their advantages, and when to use them.
Additionally, you will learn about tools like Apache Sqoop for efficiently transferring data between Hadoop and relational databases, Apache Flume for collecting and moving large amounts of log data, and Apache Kafka for building real-time data pipelines.
The course covers troubleshooting and optimization techniques, including exploring logs, tuning MapReduce jobs, and optimizing joins in Pig and Hive.
You will also learn about schema management and evolution with Avro and Kafka Schema Registry.
Throughout the course, you will work on assignments and real-world projects, solidifying your understanding of the concepts covered.
Big Data and Hadoop for Beginners - with Hands-on!
You’ll start by learning what Big Data is and the various job roles available in this field.
The course provides an overview of technology trends and salary analysis to help you understand the market demand.
Moving on, you’ll dive into Hadoop, the core technology for Big Data processing.
You’ll learn about the Hadoop ecosystem, the differences between versions 1.x and 2.x, and how it compares to traditional ETL vs ELT approaches.
The course covers different Hadoop vendors and guides you through installing Hadoop locally and on the cloud.
You’ll gain hands-on experience managing the Hadoop Distributed File System (HDFS) from the command line.
The course then focuses on two key components of the Hadoop ecosystem: Hive and Pig.
With Hive, you’ll learn about its architecture, data model, and how it handles different file formats like Text, Parquet, RCFile, and ORC.
You’ll explore the similarities and differences between SQL and HQL (Hive Query Language), and learn how to create User-Defined Functions (UDFs) and User-Defined Aggregate Functions (UDAFs) in Hive.
For Pig, you’ll understand its architecture, data model, and how Pig Latin works.
You’ll compare SQL with Pig and learn to create UDFs in Pig.
The course includes hands-on demos for both Hive and Pig to reinforce your learning.
Additionally, you’ll learn about designing data pipelines using Pig and Hive, and the concept of a Data Lake.
The course includes two practical exercises: analyzing taxi trips data and designing a Hive UDF.
These exercises will help you apply the concepts you’ve learned in real-world scenarios.
Learning Apache Hadoop EcoSystem- Hive

The course starts by explaining what Hive is, its motivation, and use cases, making it clear what you’re getting into.
It also covers what Hive is not, so you understand its limitations.
You’ll get a recap of Hadoop to ensure you have the necessary foundation.
Then, the course dives into the Hive architecture and its different modes, including the important Hive Server 2 concepts.
After solidifying these basics with quizzes, you’ll move on to the hands-on part.
The installation and configuration section is comprehensive, covering CDH, CM, and setting up a VM for demos.
You’ll learn Hive shell commands, configuration properties, and how to integrate with MySQL.
Once you have the environment set up, the real fun begins.
The course covers databases, datatypes, and the key concepts of schema on read and schema on write in Hive.
You’ll work with internal and external tables, partitioning for efficient data organization, and bucketing for performance optimization.
Quizzes reinforce your understanding of these practical topics.
But it’s not just theory - you’ll see how Hive is implemented in real-time projects.
The course even touches on auditing in Hive, which is crucial for production environments.
If you face any issues, there are dedicated sections on troubleshooting infrastructure and user problems in Hive.
With hands-on demos, quizzes, and a focus on practical skills, you’ll be well-equipped to work with Hive after completing this course.
Master Big Data - Apache Spark/Hadoop/Sqoop/Hive/Flume/Mongo

You’ll start by learning the fundamentals of Big Data and setting up a Google Cloud cluster for hands-on practice.
The course then dives into Sqoop, a tool for efficiently transferring data between relational databases and Hadoop.
You’ll learn how to import and export data using Sqoop, work with different file formats like Parquet and Avro, and handle incremental appends.
Next, you’ll explore Apache Flume, a distributed service for collecting, aggregating, and moving large amounts of log data.
You’ll set up Flume and learn how to move data from sources like Twitter and NetCat to HDFS.
The course also covers Apache Hive, a data warehouse system built on top of Hadoop.
You’ll learn how to create and manage Hive databases, tables, and partitions, as well as perform analytics using Hive’s SQL-like query language.
A significant portion of the course is dedicated to Apache Spark, a powerful open-source engine for large-scale data processing.
You’ll dive into Spark’s core concepts, such as RDDs (Resilient Distributed Datasets), Dataframes, and Spark SQL.
You’ll learn how to perform transformations and actions on RDDs, work with Dataframes and Spark SQL, and even integrate Spark with Cassandra and MongoDB.
The course also introduces you to the IntelliJ IDE, where you’ll learn how to set up Spark projects and write Spark applications in Scala.
Additionally, you’ll gain experience running Spark on different platforms like Yarn/HDFS, Google Cloud Storage, and Amazon EMR.
Throughout the course, you’ll work with real-world datasets and tackle practical examples, such as filtering error logs, calculating word frequencies, analyzing customer orders, and more.
A Big Data Hadoop and Spark project for absolute beginners

The course starts by introducing you to fundamental Big Data and Hadoop concepts like HDFS, MapReduce, and YARN.
You’ll get hands-on experience storing files in HDFS and querying data using Hive.
From there, it dives deep into Apache Spark, which is a powerful tool for data processing.
You’ll learn about RDDs, DataFrames, and Spark SQL, as well as how to use Spark for data transformation tasks.
The course even includes a project where you’ll apply your Hadoop and Spark skills to clean marketing data for a bank.
But the real strength of this course is its focus on practical, real-world skills.
You’ll learn how to set up development environments for Scala and Python, structure your code, implement logging and error handling, and write unit tests.
There are entire sections dedicated to creating data pipelines that integrate Hadoop, Spark, and databases like PostgreSQL.
The syllabus also covers more advanced topics like Spark Structured Streaming, reading configurations from files, and using AWS services like S3, Glue, and Athena to build a serverless data lake solution.
And with the addition of Databricks Delta Lake, you’ll gain insights into the modern data lakehouse architecture.
What’s impressive is how the course guides you through the entire data engineering journey, from basic concepts to building robust, production-ready data pipelines.
You’ll not only learn the technologies but also best practices for coding, testing, and deploying your data applications.
Become a Hadoop Developer |Training|Tutorial

You will start by understanding the fundamentals of big data and why Hadoop is needed to process large datasets.
The course covers the core components of Hadoop, including HDFS (Hadoop Distributed File System) and MapReduce.
You will learn how to set up Hadoop on Linux (Ubuntu) and navigate through various HDFS commands.
The course dives deep into the architecture of HDFS and how data is stored and processed within the system.
You will also gain hands-on experience running your first MapReduce program and understanding the concepts behind mappers, reducers, and combiners.
The course explores different types of MapReduce programs, including classic MapReduce and YARN (Yet Another Resource Negotiator).
You will learn about job scheduling, shuffle and sort mechanisms, and performance tuning techniques.
Advanced MapReduce concepts like counters, partitioners, and join operations are also covered.
In addition to Hadoop’s core components, you will be introduced to the Hadoop ecosystem, including Pig (a high-level data flow language), Hive (a data warehousing solution), and Sqoop (for transferring data between Hadoop and relational databases).
The course prepares you for the CDH-410 Certification Exams, with practice exams and recommendations for further study.
Throughout the course, you will work with quizzes and hands-on exercises to reinforce your understanding of the concepts.
You will learn how to troubleshoot and handle failure scenarios in both classic MapReduce and YARN environments.
Learn By Example: Hadoop, MapReduce for Big Data problems

The course starts by introducing you to the concept of Big Data and why it’s a big deal in today’s world.
You’ll learn about the paradigm shift from serial to distributed computing and how Hadoop fits into this picture.
The course then dives into the core components of Hadoop - HDFS (the distributed file system) and MapReduce (the programming model).
You’ll learn how to install Hadoop in different modes, from a local environment to a full-fledged cluster.
The “Hello World” of MapReduce is covered in detail, helping you understand the mapper, reducer, and job components.
As you progress, you’ll learn advanced techniques like using combiners to parallelize the reduce phase, leveraging the Streaming API to write MapReduce jobs in languages like Python, and configuring YARN for resource management.
The course also covers customizations like accepting command-line arguments, configuring job properties, and writing custom partitioners and comparators.
Interestingly, you’ll learn how to build an inverted index (the core of search engines) using MapReduce and work with custom data types like WritableComparable.
The course even touches on testing MapReduce jobs with MRUnit.
Input/output formats, partitioning, and secondary sorting are also covered.
The syllabus includes practical applications like building recommendation systems using collaborative filtering, using Hadoop as a database (with SQL-like operations), and implementing K-Means clustering.
Finally, you’ll learn how to set up a Hadoop cluster manually or using Cloudera Manager on Amazon Web Services.