“Half the money I spend on advertising is wasted; the trouble is I don’t know which half.” John Wanamaker (1838 - 1922)
Knowing where to spend an advertising budget has always been a big problem for advertisers.
The gold standard is testing, which every respectable advertiser does often.
It goes back to the 1920s when Claude Hopkins published the still relevant “Scientific Advertising” talking about “measuring keyed returns”.
Imagine putting ads into two newspapers, but each ad has a different phone number for people to call. You can measure which brings you the best ROI.
Today we have attribution solutions that try to do the same for online ads (conversion tracking pixels).
Some of these tools consider multiple times that people saw or interacted with an ad (multi-touch attribution, or MTA) and others give credit to a specific point in the customer journey (like last-click attribution on Meta).
Multi-touch attribution can help us test ads and know with reasonable confidence which ones are driving more conversions.
But a few challenges remain:
- It’s hard to track people across multiple devices. People can see an ad on the Facebook app, google it on their tablet and then type the URL on their computer to make the purchase.
- Privacy-enhancing tools (like ITP/iOS 14) are making it even harder to track the full customer journey.
This is where marketing mix models can help.
What Are Marketing Mix Models?
To put it simply: it’s a way to statistically estimate how much each advertising channel contributes to our revenue.
Here I use “channel” very loosely.
It can be a platform, a placement, a creative, an audience, a keyword… Any way we can break down our campaigns.
One caveat is that they don’t find causality (like testing).
We can’t say for sure that a channel caused an increase in revenue, but only how well it correlates to our revenue.
It’s an additional tool to help us decide where to put the ad dollars that takes into account all the touchpoints.
What You Need To Know About The Data I Used
The data for this marketing mix modeling case study comes from buying online ads for my courses.
I ran ads on Facebook, Instagram, Youtube, Google Search, and Display in Brazil.
The total spend in US dollars is low five-figures. ROAS is positive.
I have a blog, a Youtube channel, and a few social media accounts that get organic traffic.
This covers 95% of places where people can discover my course.
This is private ad spending and sales data so I will not make it available.
It goes from January 2021 to March 2022 (66 weeks).
My Modeling Approach
I found two off-the-shelf, open-source implementations of marketing mix models: Robyn and LightweightMMM.
Both are experimental tools being developed by competent people at Meta and Google. They seem equally adequate for my use case.
I chose LightweightMMM because it’s in Python. Robyn is in R and it has been a long time since I last coded anything in R.
LightweightMMM is a Bayesian linear model. You can see all the details on the GitHub repo.
These are the decisions I had to make before fitting the model.
1. Which Frequency And Granularity To Use?
My course has a very small market.
I don’t sell one every day but I sell at least one almost every week, so I decided to aggregate my data by week.
For granularity I went with the high-level campaign platform (e.g: Google Search, Facebook, Instagram) that had any data for the period.
A rule of thumb you can use from machine learning is: try to have at least 10 rows for each column in your dataset. This is not set in stone, but helpful to know.
I have 8 channels, of which 5 have 95%+ of the spend, and 66 weeks of data, so we are fine.
2. How To Deal With Organic Data?
LightweightMMM has baseline, trend, and seasonality coefficients, so it seems I don’t need to include organic data as a media channel.
The prior for the media effects coefficients uses the scaled spend as the variance, so setting cost equal to zero or some tiny value throws off the estimates.
Two options left: not using organic channels or using an uninformative prior as cost (setting every cost to 1).
I chose the first one, as it’s important to take real costs into account as priors.
Running uninformative priors inflated organic channel effects which goes against other tests I made.
In one of them I turned all ads off for 3 months and sales fell to a third of the previous months.
My sales are very stable across the year, so ads clearly make a difference.
3. What To Use As Media Data (Inputs)?
I always heard about using the money spent as input data to marketing mix models. It makes sense when we talk about TV and Radio ads.
Robyn and LightweightMMM suggest using other metrics like impressions or clicks.
It makes sense for online ads, as the CPM for channels will be different and impressions and clicks are direct ways to measure how many people we reached.
So I chose impressions.
4. Which Adstock Model To Use?
Adstock is the “prolonged or lagged effect of advertising on consumer purchase behavior.”
It helps to account for the effects of multiple touchpoints a customer sees through time before converting.
My course is not priced at an impulse purchase level, so I don’t expect people that never heard of me to buy it after seeing one ad.
I like model_name=“carryover” simply because it makes more sense to me to have a limited lag effect instead of the infinite “adstock” one.
A more data-scientisty way to find the right one is using a traditional validation split, which brings us to…
5. How To Create An Accurate Model?
The gold standard for evaluating machine learning models is splitting the data into training (which we use to fit the model, find the coefficients) and validation data (which we use to assess the accuracy of predictions on data the model never saw, aka the future).
Not only that, but we can use it to tune parameters like the degrees of seasonality and the adstock model.
I used 2021 as training (52 weeks) and 2022 as validation (14 weeks).
It’s a tiny dataset, so we have to be careful, but I found that degree_seasonality=1 and model_name=“carryover” gave me significantly better accuracy.
(For the data scientists, I evaluated RMSE and MAE, it was the best in both).
This is important because if the model can reliably predict the revenue from weeks it never saw, its media effects coefficients must be close to the real ones.
After finding the parameters, I refitted the model with all the data.
With all these questions solved, let’s talk about the results.
So, Are Marketing Mix Models Useful?
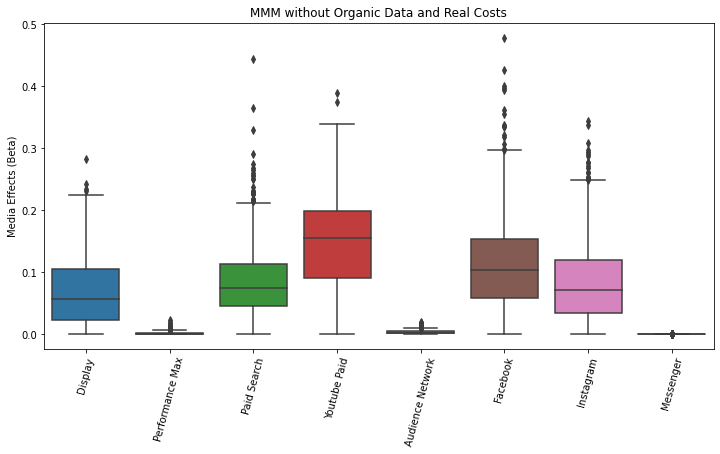
On the Y-axis we see the media effect coefficients (beta) for each channel. Higher means the channel impressions explain more of the revenue.
Reminder: these models can’t pinpoint causality, only tests can, so what we are seeing is a correlation study.
How To Validate These Effects?
One way to see if the estimated effects make sense is to compare them to the reported conversion values for each platform. If they at least rank in the same order, it’s a positive sign.
I summed up all the reported conversion values inside each platform and compared them to the estimated media effects.
The order of importance of channels according to the on-platform attribution and the marketing mix model is:
| Rank | On-platform Attribution | Marketing Mix Model |
|---|---|---|
| 1 | Youtube | Youtube |
| 2 | Search | |
| 3 | Search | |
| 4 | Display | |
| 5 | Display |
They seem to go in the same direction, good. Some things to note:
- Most of my Search campaigns were branded so it may very well be that people saw the ads elsewhere and googled.
- Youtube is my biggest organic channel so I have lots of remarketing potential there.
- Facebook and Instagram use last-touch attribution.
- Display was used for remarketing.
- 80%+ of my sales happen on desktops, so I expect mobile-heavy platforms to underreport.
- I believe Google is more accurate in tracking conversions in Brazil as 88% of phones use Android and 77% of desktops use Chrome.
- My target audience is very tech-savvy so I expect higher-than-average use of anti-tracking software. (I don’t use it because it’s hypocritical, as my work depends on collecting data)
I am not advertising on any Meta platform because I want to learn more about Google Ads, but I clearly should be.
This model would be essential if I had a larger market, higher sales volume, and spent more across the full funnel.
My plan is to use this model to optimize my Google ad spend together with the on-platform conversion tracking and Google Analytics 4.
As I will be focused on two campaigns (Performance Max and Search) I will use devices, audiences, and placements as channels (e.g: buying paid search only on computers or excluding audiences, age/income brackets).
To answer the original question: yes, after trying it, I believe marketing mix models are useful.
Next, you can read this tutorial with code on how to create marketing mix models using LightweightMMM.