
One can’t simply use a random train-test split when building a machine learning model for time series
Doing it would not only allow the model to learn from data in the future but show you an overoptimistic (and wrong) performance evaluation.
In real-life projects, you always have a time component to deal with.
Changes can happen in nanoseconds or centuries, but they happen and you are interested in predicting what will come next.
Today I will teach you three simple and popular methods you can use to build a correct validation strategy for your time series projects.
Simple Time Split Validation
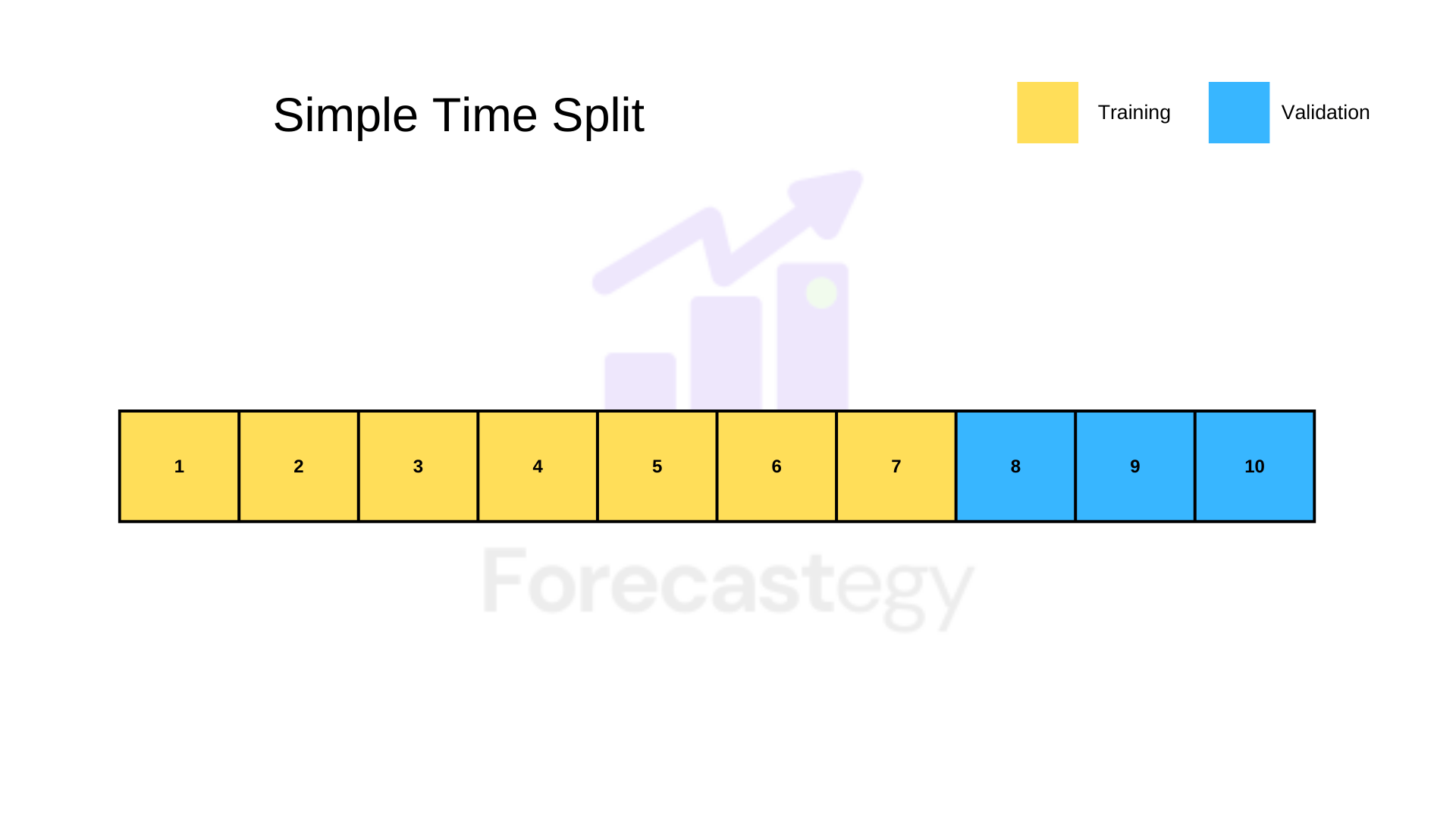
You pick a time point in your series and use everything that comes before it as training data and everything that comes after it as validation.
I recommend you leave at least 50% of your data as training.
series = pd.Series(np.random.uniform(0,1,365),
index=pd.date_range('2021-01-01', '2021-12-31', freq='D'))
train = series.loc['2021-01-01':'2021-07-31']
valid = series.loc['2021-08-01':'2021-12-31']
It’s very important to do it before you start creating features and doing any preprocessing, to make sure you don’t accidentally use future data.
This method is already good enough for most applications.
And certainly much better than using a simple random split, but we can go further.
Sliding Window Validation
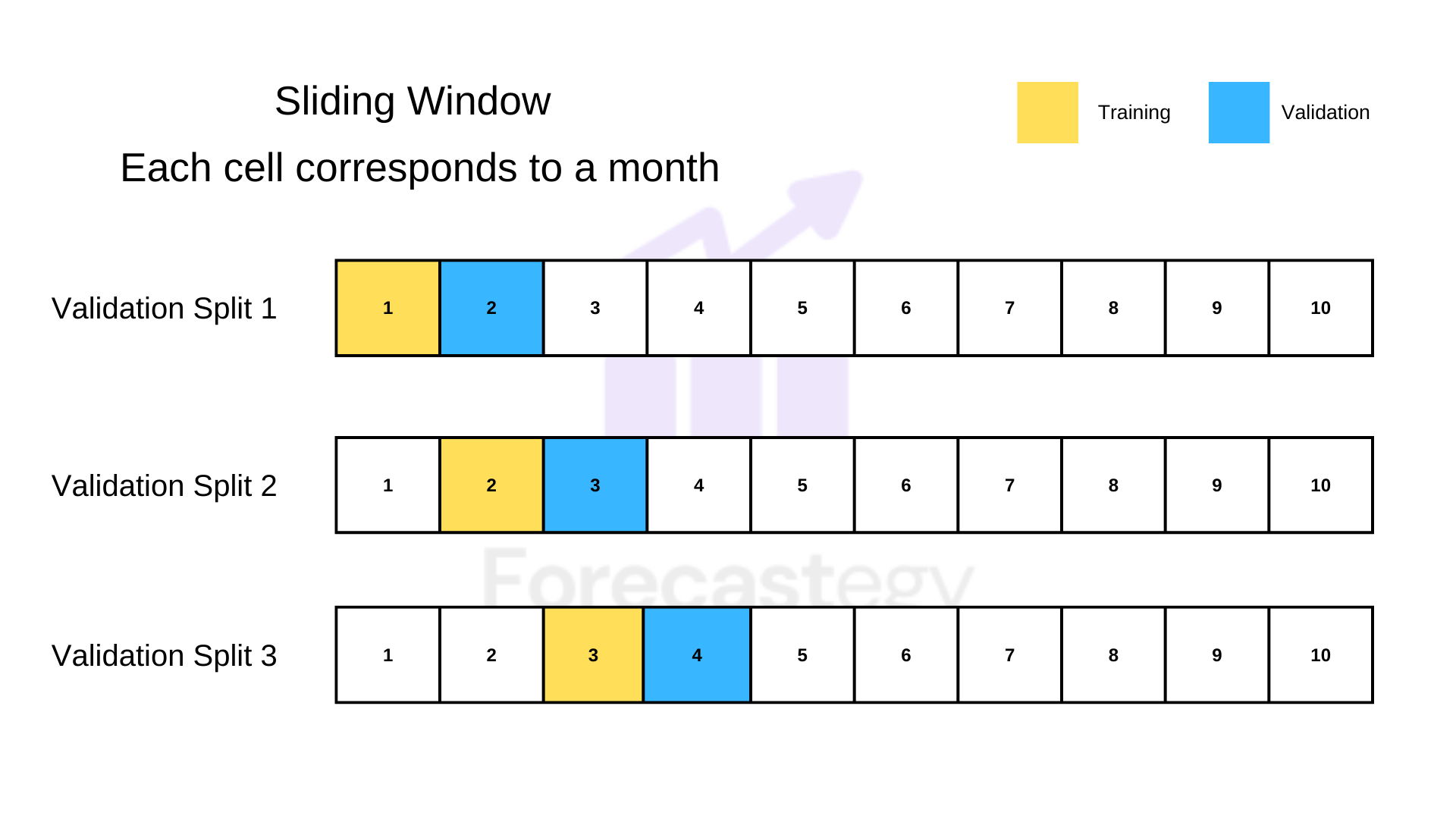
Here you will take a fixed-size window for training and another for validation.
Always respecting the time order of the data. Training in the past and validation in the future.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
delta = date - pd.offsets.MonthBegin(1)
train = series.loc[delta:date-pd.offsets.Day(1)]
valid = series.loc[date:date+pd.offsets.MonthEnd(1)]
The difference is that instead of using just a single split, like in the first method, you will “slide” this window across time and get something similar to cross-validation.
Let’s say you have daily data for a year and you choose to use a month for training and a month for validation.
First, you take January data as training and February as validation.
Then you take February as training and March as validation, and so on.
This method allows you to have a more robust estimate of your model performance over time by aggregating metrics over multiple splits, just like cross-validation.
Another useful way to use this split is by keeping your training set fixed and varying the validation set.
For example, always using January as training but checking how well the model does in February, then March, and so on.
This is a great way to find out how your model degrades with time and give you an idea of when you should retrain it when deployed.
In practice, I start with the simple time split and then move to the sliding window method, as it’s the closest we have to what we do in production.
This is also known as rolling window validation.
Expanding Window Validation
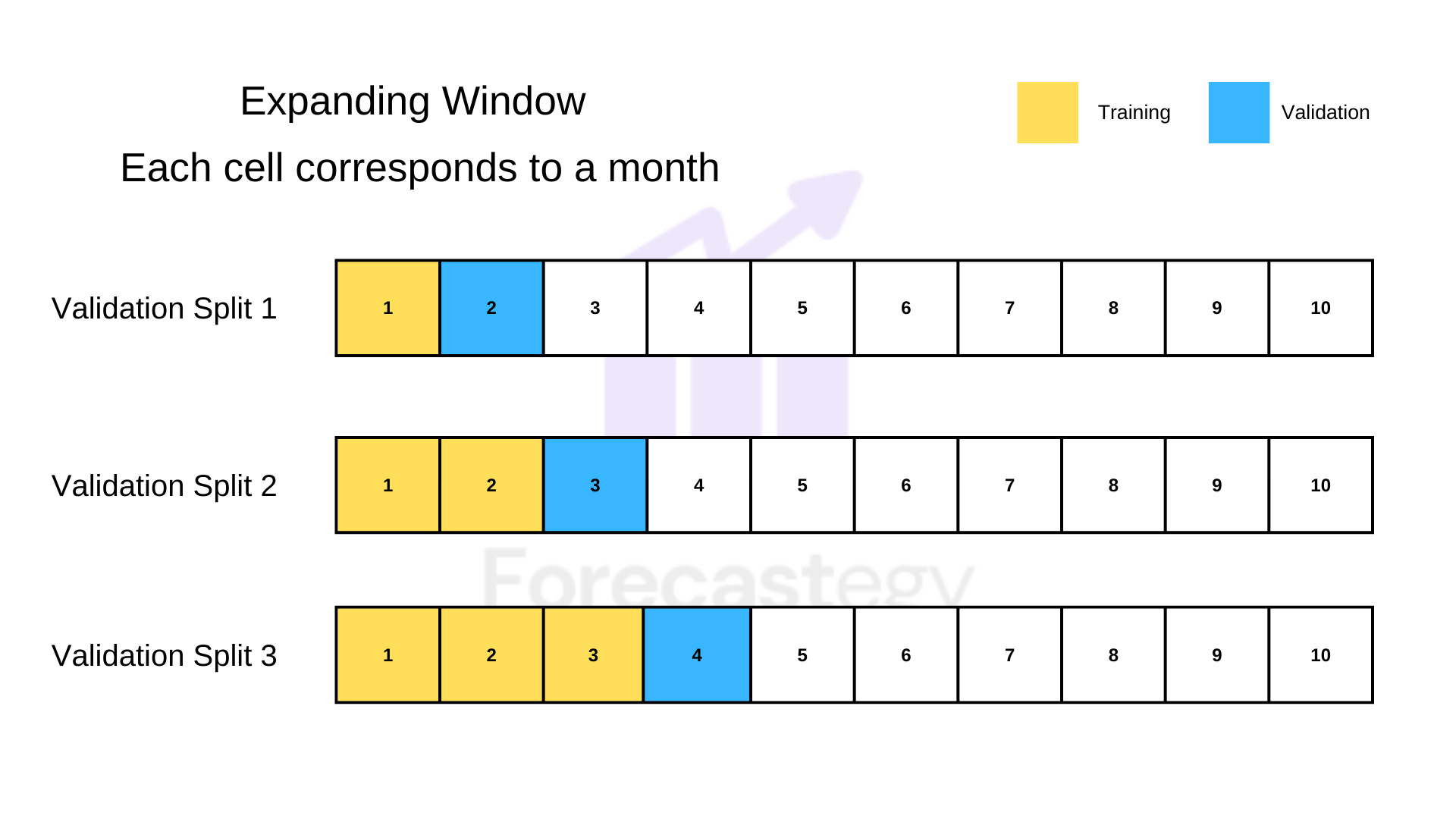
This usually means expanding the training window to have more and more data.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
train = series.loc[:date-pd.offsets.Day(1)]
valid = series.loc[date:date+pd.offsets.MonthEnd(1)]
In our example, at first, you train using January data and validate using February.
Then you use January and February as training, and validate in March, and so on.
Every time we are increasing the size of our training dataset, but keep the validation dataset with the same size.
Although it’s generally good to use more data to train models, your model can get stale by looking too much at old patterns that may have changed.
I only use this method when I have a small amount of new data coming every time.
This is also known as walk-forward validation.
Inserting a Gap Between Training and Validation
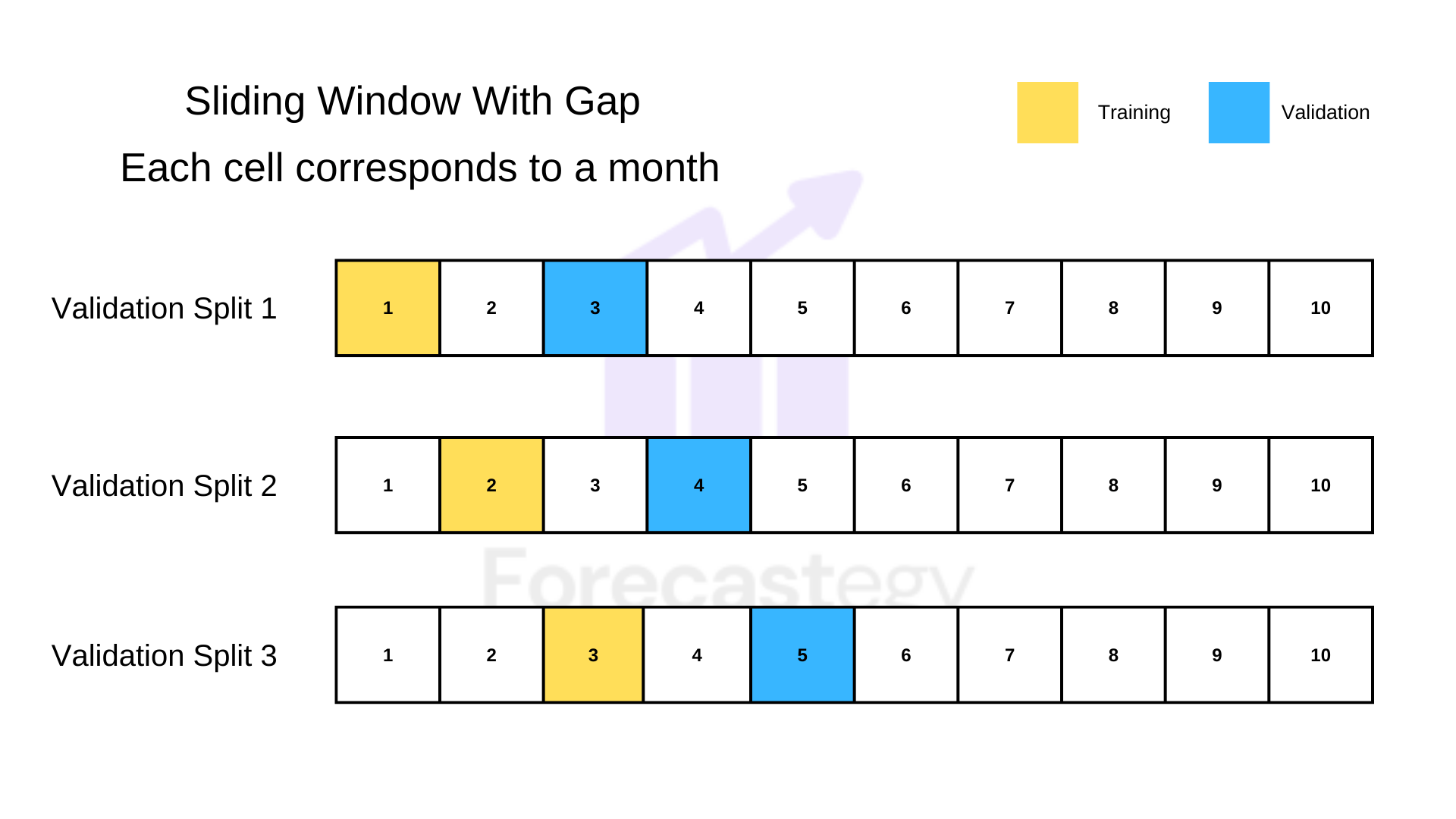
A way to make your validation even more robust is to introduce a gap between the last training set timestamp and the first validation timestamp.
It can be used with any of the split methods mentioned above.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
delta = date - pd.offsets.MonthBegin(1)
train = series.loc[delta:date-pd.offsets.Day(1)]
valid = series.loc[date+pd.offsets.MonthEnd(1)+pd.offsets.Day(1):date+pd.offsets.MonthEnd(2)]
This is useful in cases where data is not available immediately or you want to use the most recent data to evaluate your trained model in an automatic deployment platform.
In our example, we could use January to train the model and March to validate.
Another way would be using January to train, February to do hyperparameter search, and then validating the model in March (maybe retraining with January and February after finishing the search).
Keep these methods in your toolbox and you will be very well prepared to deal with any time series modeling task in your machine learning journey.
Using Scikit-learn’s TimeSeriesSplit for Cross-Validation
Now that you have an understanding of different validation strategies for time series, let’s talk about how to automate this process using scikit-learn’s TimeSeriesSplit function.
This tool automates the expanding window method we discussed earlier.
Here is a simple example of how you can use it:
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(series):
train = series[train_index]
valid = series[test_index]
In this snippet, the TimeSeriesSplit object is initialized with a specified number of splits (5 in this case).
Inside the loop, we then use the indices provided by TimeSeriesSplit to create our training and validation sets.
A crucial thing to note is how this works.
The split method returns indices, not actual datasets. These are then used to ‘slice’ the original time series into the training and validation sets.
On the first iteration, the method uses the first 20% of the data for training and the next 20% for validation.
On the second iteration, it uses the first 40% for training and the next 20% for validation.
This process continues until all the data has been used.
It’s important to remember, TimeSeriesSplit respects the temporal order of your data, ensuring that the ‘future’ data is not used to train your model.
So make sure your data is sorted before using this method.