In machine learning, particularly in the field of recommendation systems and natural language processing, we often deal with categorical features.
These features can be anything from user IDs, product IDs, to words in a text.
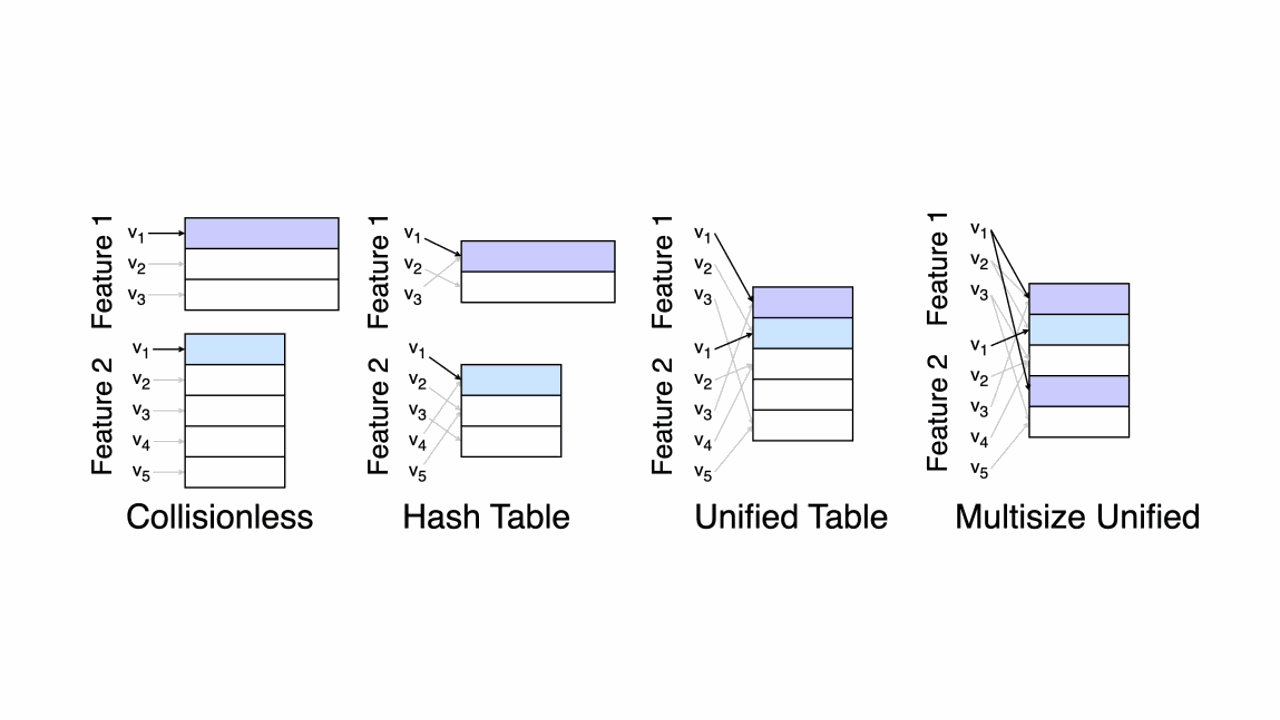
One common practice to handle these categorical features is to represent them as embeddings, which are dense vector representations learned during the training process.
However, when dealing with web-scale machine learning systems, the number of unique categorical features can be extremely large, leading to a massive number of embeddings.
This poses significant challenges in terms of memory usage and computational efficiency.
Moreover, each categorical feature typically requires its own embedding table, further complicating the model architecture and the training process.
The method presented in the paper “Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems” and implemented in the provided code addresses these challenges by introducing a unified embedding framework.
This framework uses a single embedding table to represent all feature vocabularies, allowing for parameter reuse and improved efficiency in terms of both space and time.
This is particularly critical for models that must fit into limited GPU/TPU memory or obey latency and serving cost constraints.
The code provided implements this unified embedding framework and applies it to a simple feed-forward neural network trained on the MovieLens dataset.
The MovieLens dataset contains user ratings for movies, along with some user information.
The goal is to predict the rating a user would give to a movie, which is a common task in recommendation systems.
Implementing a Shared Embedding Table in PyTorch
This code defines a PyTorch module for the Unified Embedding as described in the paper.
import torch
import torch.nn as nn
import xxhash
The code starts by importing the necessary libraries.
torch is the PyTorch library, which provides all the necessary tools for creating and training neural networks.
nn is the neural network module of PyTorch, which contains functions and classes for building neural networks.
xxhash is a Python library for hashing, which is used in this code to create a unique hash for each feature.
class UnifiedEmbedding(nn.Module):
def __init__(self, emb_levels, emb_dim):
super(UnifiedEmbedding, self).__init__()
self.embedding = nn.Embedding(emb_levels, emb_dim)
The UnifiedEmbedding class is defined as a subclass of nn.Module, which is the base class for all neural network modules in PyTorch.
The __init__ method initializes the UnifiedEmbedding object with an embedding table of size emb_levels and dimension emb_dim.
If you are new to embeddings, think about them as a lookup table.
The embedding table is a matrix of size (emb_levels, emb_dim), where emb_levels is the number of unique values in the feature and emb_dim is the dimension of the embedding.
Each row of the embedding table is an embedding vector, which is a vector of size emb_dim that represents a unique value in the feature.
The nn.Embedding class is a simple lookup table that stores embeddings of a fixed dictionary and size.
def forward(self, x, fnum):
x_ = torch.LongTensor(x.shape[0], len(fnum))
for i in range(x.shape[0]):
for j, h_seed in enumerate(fnum):
x_[i, j] = xxhash.xxh32(x[i], h_seed).intdigest() % self.embedding.num_embeddings
The forward method is where the actual computation happens.
It takes as input a tensor x of shape (batch_size, 1) with the feature values, and a tuple fnum containing the number of lookups for the feature.
It then creates a new tensor x_ of shape (batch_size, n_lookups).
For each element in x, it computes a hash using xxhash.xxh32 with a different seed for each lookup.
This is what allows the multisize part of the Unified Embedding, where some features can use more than a single embedding vector from the shared embedding table.
return self.embedding(x_).reshape(x_.shape[0], -1)
Finally, the forward method returns the embeddings for the hashed features.
It does this by passing x_ to self.embedding, which gets back the corresponding embeddings from the embedding table.
Let’s say the feature has 2 lookups, one hashed to embedding position 1 and the other to position 21.
The method will return the embeddings for positions 1 and 21, which will be concatenated into a single vector of size (batch_size, 2 * emb_dim).
Testing on a Movie Recommendation Dataset
This code defines a simple feed-forward neural network and trains it on a sample of the MovieLens dataset.
I wanted to run the code to make sure it worked and reduced the loss on the training and validation sets.
The MovieLens dataset contains user ratings for movies, along with some user information.
The NN uses the Unified Embedding for feature multiplexing instead of the usual one-hot encoding or colisionless embedding.
from ue import UnifiedEmbedding
import torch.optim as optim
import torch.nn as nn
import torch
import polars as pl
import pathlib
The code starts by importing the necessary libraries.
ue is the module containing the UnifiedEmbedding class defined in the previous code.
torch.optim is the optimization module of PyTorch, which contains optimization algorithms like SGD and Adam.
polars is a DataFrame library for data manipulation and analysis.
pathlib is a standard Python library for handling filesystem paths.
class SimpleNN(nn.Module):
def __init__(self, emb_levels, emb_dim, col_map):
super(SimpleNN, self).__init__()
self.col_map = col_map
self.ue = UnifiedEmbedding(emb_levels, emb_dim)
in_dim = sum([len(fnum) for _, fnum in col_map]) * emb_dim
self.fc1 = nn.Linear(in_dim, 64)
self.relu = nn.ReLU()
self.out = nn.Linear(64, 1)
The SimpleNN class is defined as a subclass of nn.Module.
The __init__ method initializes the SimpleNN object with a UnifiedEmbedding and two fully connected layers (fc1 and out), with a ReLU activation function (relu) in between.
The col_map is a list of tuples, where each tuple contains a column name and a tuple of hash seeds for the Unified Embedding.
It defines how many lookups each feature will use from the Unified Embedding.
def forward(self, x):
x_ = list()
for col, fnum in self.col_map:
x__ = self.ue(x.select(pl.col(col)).to_numpy().squeeze(), fnum)
x_.append(x__)
x_ = torch.cat(x_, dim=1)
out = self.fc1(x_)
out = self.relu(out)
out = self.out(out)
return out
The forward method takes as input a DataFrame x and computes the embeddings for each column specified in col_map using the UnifiedEmbedding.
The embeddings are then concatenated along the second dimension to form a single tensor.
This tensor is passed through the fully connected layers and the ReLU activation function to produce the output.
We use a function named load_movielens() to loads and process the MovieLens dataset.
The function reads user data and ratings data from two separate files, merges them, and then splits the merged data into training and validation sets based on the timestamp.
It also extracts the labels (ratings) for both sets.
def load_movielens():
The function starts by defining the path to the dataset files.
path = pathlib.Path("path")
Next, it reads the user data from the “users.dat” file.
Each line in the file is split into different fields: UserID, Gender, Age, Occupation, and Zip-code.
The function only keeps the UserID, Age, Occupation, and Zip-code in a dictionary named user_ids.
user_ids = dict()
with open(path / "users.dat") as f:
for line in f:
row = line.strip().split("::")
user_ids[row[0]] = {"age": row[2], "occupation": row[3], "zip": row[4]}
Then, it reads the ratings data from the “ratings.dat” file.
Each line in the file is split into different fields: UserID, MovieID, Rating, and Timestamp.
The function also adds the corresponding user’s Age, Occupation, and Zip-code from the user_ids dictionary to each rating record.
ratings = list()
with open(path / "ratings.dat") as f:
for line in f:
row = line.strip().split("::")
row_ = {"user_id": row[0],
"movie_id": row[1],
"rating": row[2],
"timestamp": row[3],
"age": user_ids[row[0]]["age"],
"occupation": user_ids[row[0]]["occupation"],
"zip": user_ids[row[0]]["zip"]}
ratings.append(row_)
The function then converts the list of rating records into a DataFrame, casts some columns to integer type, and filters out users with IDs greater than or equal to 100.
data = pl.DataFrame(ratings).with_columns([
pl.col("user_id").cast(pl.Int32).alias("user_id_num"),
pl.col("timestamp").cast(pl.Int32).alias("ts_num"),
pl.col("rating").cast(pl.Int32).alias("rating_num")
]).filter(pl.col("user_id_num") < 100)
Next, it calculates the median timestamp and uses it to split the data into training and validation sets.
The training set includes records with timestamps less than the median, and the validation set includes records with timestamps greater than or equal to the median.
mid = data["ts_num"].median()
train = data.filter((pl.col("ts_num") < mid))
val = data.filter(pl.col("ts_num") >= mid)
Finally, it extracts the labels (ratings) for the training and validation sets and returns them along with the sets.
train_labels = train.select(pl.col("rating_num")).to_numpy()
val_labels = val.select(pl.col("rating_num")).to_numpy()
return train, val, train_labels, val_labels
Next, we define the main code that loads the MovieLens dataset, creates a SimpleNN object, and trains it using the Adam optimizer and mean squared error loss.
train, val, train_labels, val_labels = load_movielens()
This line calls the load_movielens function to load the MovieLens dataset and split it into training and validation sets.
The function also returns the corresponding labels (ratings) for the training and validation sets.
lr = 0.001
epochs = 100
Here, we set the learning rate lr for the optimizer and the number of training epochs.
col_map = [("user_id", (0,1)),
("movie_id", (2,3)),
("age", (4,)),
("occupation", (5,)),
("zip", (6,))]
col_map is a list of tuples where each tuple contains a column name and a tuple of hash seeds for the Unified Embedding.
Like said before, it defines how many lookups each feature will use from the Unified Embedding to allow for different embedding sizes for different features.
ffnn = SimpleNN(1000, 10, col_map)
We create an instance of the SimpleNN class, passing the number of embedding levels, the embedding vector size, and the column map.
criterion = nn.MSELoss()
optimizer = optim.Adam(ffnn.parameters(), lr=lr)
We define the loss function (criterion) to be the mean squared error loss, which is suitable for regression tasks like rating prediction.
We also define the optimizer to be Adam, a popular choice for training neural networks, and pass the parameters of our model and the learning rate to it.
for epoch in range(epochs):
optimizer.zero_grad()
outputs = ffnn(train)
loss = criterion(outputs, torch.FloatTensor(train_labels))
loss.backward()
optimizer.step()
This is the main training loop.
For each epoch, we zero the gradients, compute the model’s predictions (outputs) on the training set, compute the loss between the predictions and the true ratings, backpropagate the loss to compute the gradients, and update the model’s parameters using the optimizer.
with torch.no_grad():
ffnn.eval()
val_outputs = ffnn(val)
val_loss = criterion(val_outputs, torch.FloatTensor(val_labels))
print(f"Epoch: {epoch}, Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}")
ffnn.train()
After each epoch, we switch the model to evaluation mode and compute its predictions and loss on the validation set.
We do this inside a torch.no_grad() context to tell PyTorch that we don’t need to compute gradients here, which saves memory.
We then print the training and validation losses for this epoch and switch the model back to training mode.