Writing this article will very likely get my Twitter account banned, as I am publicly pleading guilty to breaking the terms of service. Anyway, it’s worth it.
To learn more about how conversion modeling works end-to-end, I threw machine learning at a well-known black hat strategy to grow a following on Twitter.
It grew my account from about 900 followers to 20,000 in about 6 months.
Here’s how it went…
Follow-Unfollow, But Smart
In any social network, if you follow people, a percentage of them will follow you back.
Some people follow everyone that follows them, others just find your profile interesting.
I compare the “X followed you” notification with an ad impression of a profile. It could be other events like “X liked your tweet” or “X liked your post”, but the most effective, by far, is the follow.
On Twitter, randomly following people got me between a 10% to 19% follow-back conversion rate. Liking a tweet got me 3%.
The unfollow part comes after a few days when you unfollow everyone and start again.
This is against the terms of service of all large social media platforms. Although I see people getting away with it all the time.
My goal was to see if I could use machine learning to predict who would follow me back and make better use of my 400 follows API rate limit (the “advertising budget”).
I defined a conversion first as: did this user follow me up to 24 hours after my follow? I unfollowed after 24h and recorded if the person was following me.
The problem is that some people will unfollow after this period and other people will not log in every day but follow when they do.
After digging more into the API, I found a cheap endpoint to get my follower ids in bulk so I just downloaded the list every time I needed to retrain the model.
Another advantage of this model is that it captures delayed follows and treats as positive examples only people that kept following.
Now it was time to define my modeling approach…
Two-Step Conversion Modeling
I worked with conversion modeling while I was at Upwork to improve the ranking system for the best freelancers for a job.
We usually do it in two steps:
- Candidate selection
- Ranking
I followed the same framework here.
Candidate Selection
Conversion modeling is usually a needle-in-the-haystack problem. You have millions of users and need to find the few that are most likely to perform the conversion action.
It’s expensive to make millions of predictions multiple times a day using a complex model with hundreds of features.
Besides, when you consider millions of users, the gain from using a complex model to find the top 10,000 is not that great compared to a simpler, cheaper model.
So the first step is using a model that has high recall: it can return a big list that contains the people that are likely to convert but is much smaller than the full user pool.
In this case, I could follow any of the 229 million Twitter users, but at 400 a day, it would take about 157 years.
Instead of following users completely at random, I had a simple heuristic to limit my candidates: get people that already followed a machine learning/data science-related account.
For example, I scraped the profiles of thousands of people that followed Andrew Ng. I think someone who follows Andrew is more likely to be interested in my profile than a random person who follows Elon Musk.
At first, this was done offline. I set up a script that would cycle through “seed” profiles and store the user objects of the latest followers. This got me a list of about 600,000 candidates.
Ranking
Following these candidates at random is likely better than following profiles at random. As I said, it got me between 10-19% of follow-back conversions.
Now the fun part starts…
What if I use machine learning to rank the people most likely to follow me back? Can I predict who these people are?
Well, you are reading this article, so yes :)
First I needed to collect labeled data. So I created a script that followed people from the candidate list at random and after 24 hours checked if the user had followed me back. If yes, positive label, if not, negative.
As I said above, with time I found an endpoint that allowed me to find the ids of people that followed me cheaply, so I stopped using the method above and just labeled as positive anyone that was following me at retraining time.
With about 2,000 samples, I trained the first model.
The features were very simple: information I could get from the API like the number of followers, number of profiles the user followed, number of tweets, etc.
This could be made much more complex if I stored snapshots of the profiles.
Recent behavior and behavior through time, in general, tend to be strong features to predict conversions, but I didn’t think it was worth the hassle.
The First Results
I immediately saw an improvement.
My follow-back conversion rate went to 25-30% consistently. But there was still room for improvement.
This was my first, “quick and dirty” solution. It was not even tuned!
After running hyperparameter tuning, I retrained it manually every 3-7 days and re-ranked every user from my candidate database. It took almost an hour.
Every time I retrained and reranked, I saw the conversion rate go up for a few days and then go back down.
Besides retraining, there was another problem: once a user was in my database, I never updated his features. So the data the model used to predict if a user would follow me now could be from 20 days ago.
Even though retraining helped, predicting using stale features is bad.
The worst part, I found one of the most important features was “how long since the user’s last tweet”.
A recency baseline is usually hard to beat when predicting behavior, so any features that show the user is active or performed a behavior recently tend to be very useful.
If the user tweeted a lot but stopped using Twitter, the model would be fooled. Same thing if the user didn’t tweet in a year, but decided to be active now.
So I implemented an endpoint that would call Twitter’s API, get fresh features for the top 1,000 candidates ranked offline, and rerank them.
With more data, I was able to use the profile description as a feature. I got a random pretrained text model from HuggingFace, ran PCA, and used the components as features.
Profile description is a surprisingly bad feature to predict who will follow me back, but it helps a bit, so I kept it.
As I got more data I tested using the pretrained model output directly, but it didn’t improve the results, so I kept the PCA.
These improvements put the conversion rate stable around the 28-32% range.
Can We Do Better?
As you can notice, the improvements were getting harder to get. This is normal in machine learning.
I decided to look more into the data and try to find patterns in the profiles of people that followed me back.
This is something I learned from Andrew Ng and saw many people do on Kaggle to find problems with the data: error analysis.
I noticed a few patterns like the user country and a few job descriptions on the profiles that tended to follow me more.
Using these as features didn’t help, so I tried finding data science and software development seed profiles from specific countries to get candidates.
And I finally got the time to set up automatic daily retraining of the model.
These improvements helped me reach a peak of 46% conversion rate, but it gradually went down and stabilized between 30-35%.
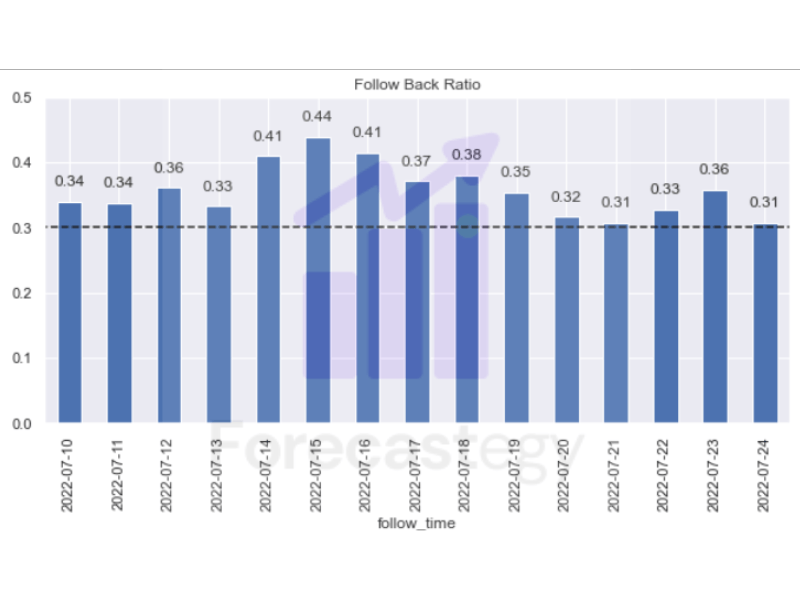
More Candidates Are Better After You Have a Good Model
A lesson I am taking from this project to any recommender project I do in the future is to pay a lot of attention to the candidate pool.
Having a good ranking model is important, but having a big pool of candidates to choose from is 60-80% of the work.
This was not completely obvious to me at first, as you can make the case that having too many candidates can pollute the pool and make the model send a lot of false positives to the top.
So having a reliable, accurate model is essential, but after that, you should feed a lot of candidates for it to get maximal performance.
Every time my model started struggling I went and found new ways to grab candidates for it to score, which gave it new life.
This is probably one of the reasons why Facebook Ads became such a powerhouse.
They have great AI and they have almost 4 billion monthly active users to show ads to. As long as their machine learning model is good enough, it will find someone to convert.
Lesson learned: give the model as much opportunity as possible to find what you want.
Was It Worth?
As a machine learning project, yes! And it was fun too.
It started simple and got more complex with time.
I learned a lot about cloud services I can use to deploy a model and a retraining pipeline in a serverless (low-cost) fashion.
I always recommend that people do an end-to-end machine learning project.
You can take this project as inspiration and build it without going against the terms of service: make a useful bot with quotes, or useful information, and use the data to improve its tweets.
The engagement in my tweets didn’t increase.
I got a few new followers that are interested in what I am tweeting, but many people that follow back already follow a lot of people, so they probably don’t even see my tweets in the feed.
So from a social media perspective, it’s an effective way to inflate your follower numbers but not to get high engagement in your tweets.
Why Twitter? Is This a Vulnerability?
I chose Twitter because it looked like the easiest social network to do it.
All the time I was using the official Twitter API. No proxies, no browsers simulating a human, nothing to cover my tracks.
I expected the API to block me on the first day. But no. As long as I stayed under the 400 follows limit, it was fine.
I only got limited once, for 3 days, when my code had a bug, and repeatedly tried to follow more than 400 users in 24 hours. Even then, after 2 days, as long as I followed only 1-2 people every 15 minutes, it worked.
If you work at Twitter, it’s a good idea to check why the API didn’t detect the bad behavior. More people can be abusing it.