
I would not have a data science career without Kaggle.
So if you are looking for a blog post bashing Kaggle, this is not the place.
Competing on Kaggle is worth it! It will teach you a lot about machine learning, give you a project to talk about in interviews, which can even help you get a job!
That said, I am not a radical that thinks Kaggle is the ultimate thing that everyone must do in order to become a data scientist.
I want to give an honest opinion coming from the perspective of someone that heavily competed but decided to “retire” a few years ago.
Some Background Context
My career path is very weird, but I think it’s an even more compelling case to show how spending time working on Kaggle competitions can help you.
I am a law school dropout that didn’t want to go back to college and decided it was a good idea to self-learn machine learning even though, at the time, almost all data science job postings required at least a Masters degree in STEM.
I saw competing on Kaggle as my only shot at showing I knew what I was doing and compensating for not having academic credentials.
Going to college would have saved me a lot of time and effort, but I still think you can benefit from Kaggle even if you are not in the same weird situation I was in.
The Good Parts Of Kaggle
The People You Meet
I had the opportunity to learn from some of the best minds in machine learning and in some cases got friendships that extended outside of Kaggle.
I have fond memories of hours discussing strategies with Giba and Leustagos via Skype during the Caterpillar (now Tube Pricing) competition.
I was always impressed by the track record of Stas Semenov and after reaching out to team up, ended up finding a friend beyond competitions.
Today you see many people looking for mass engagement on the forums or teaming up just to get medals, but the real value in Kaggle is teaming up to create relationships.
One of my biggest mistakes (in life) is trying to do everything on my own.
If you look at how many competitions top-ranked Kagglers participated in solo vs in a team, you will see that most have a high percentage of team participation.
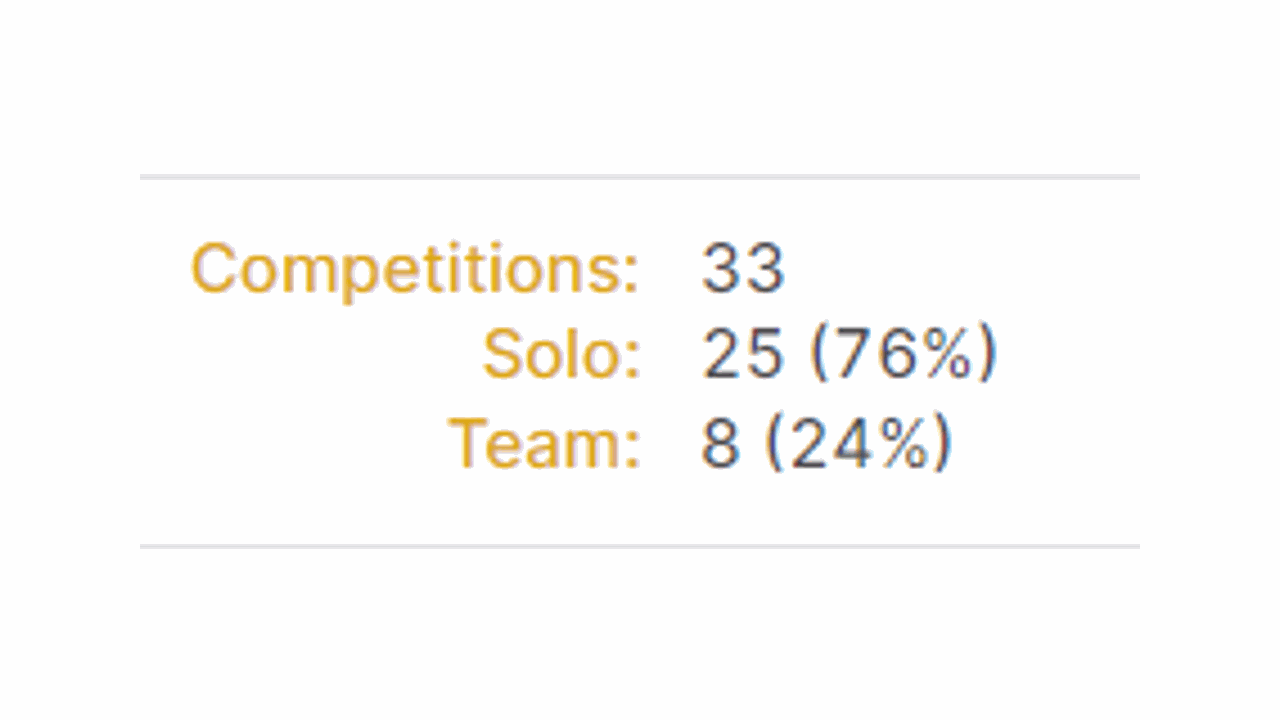
It’s much easier to get a top position and prizes if you are in a team.
A Bonus Tip To Team Up With Experienced Kagglers
The best way to attract experienced Kagglers to your team is to have a promising solution (proven by the LB position) and propose to do most of the heavy lifting.
I knew teaming up with a more experienced Kaggler would help me grow a lot, so I used the following strategy to get my first team with Giba:
At the time there were 2 competitions with the same finishing date. I talked with Giba and found out he was focused on the one I was not participating in.
I knew he liked to compete in as many challenges as possible. I had a decent solution (approximately 150 on LB) and pitched him the following: let’s collaborate, we’ll talk ideas, and I’ll take care of the lion’s share of the job.
He agreed and after a few minutes of looking at my code, he found a simple bug in my feature engineering. After fixing it, we jumped to 2nd place.
This was a huge boost to our motivation.
We got Leustagos and Josef Feigl to join the team. We all put in a lot of effort and ended up winning the competition.
Reading their code and getting a glimpse of how they thought about machine learning was better than any course I ever took.
Does Kaggle Help You Get A Job?
I had the following dialogue multiple times:
Me: “How did you find me?”
Recruiter: “I was looking at Kaggle and found your profile.”
Even if you are not keeping a high rank on Kaggle, companies actively look for Kaggle competition winners, Masters, and Grandmasters.
Search for jobs with “Kaggle” in the description on LinkedIn and you will see companies like Amazon, Microsoft, and Meta citing experience in competitions as a preferred qualification.
Some companies like NVIDIA even have a specialized team of Kaggle Grandmasters!

For freelancing/consulting it’s a hit or miss. Some clients will know about Kaggle and value it, others won’t. This will probably improve over time.
Even if you never win a competition, what you learn by working on them will help you do better at work.
Can You Make Money On Kaggle?
The prize money is usually not worth the time and effort you have to put in to win.
If you’re just starting out, it’s better to use competitions as a learning tool and not focus on the money.
The potential earnings from using the knowledge you obtain on Kaggle on other projects is astronomical.
I don’t remember exactly where I heard the following analogy about competing on Kaggle vs working as a data scientist in a company:
It’s like comparing someone that runs 5Ks to Olympic athletes. The Olympic athlete will have to go beyond the basics to get maximum performance. Just like competing on Kaggle forces you to go very deep into the task.
Although you will most likely never have to delve as deep into a task at work, the fact that you’ve done it in competitions makes it simpler and quicker to arrive at a high-performance solution.
Just don’t be blinded by thinking modeling is the only thing that matters (more on this later).
You Become Good At Writing Machine Learning Code Without Realizing It.
There is both a strategic and a “mechanical” skill component to being a good data scientist.
Kaggle is a great place to practice the mechanical part.
As you have to iterate very fast between solutions, writing code to process data and build machine learning models will become second nature.
You will also get better at using out-of-the-box machine learning libraries and always know about new libraries and methods that work in practice before most data scientists.
You Will Develop A Very Good Sense Of What Is Possible With Data And Machine Learning
This is extremely useful in many different domains outside of Kaggle.
Even though the datasets come (almost) ready for use, one exercise that helped me is trying to reverse engineer how the sponsors created it.
For example, in the recent H&M Recommendation challenge, the task was to predict which items a customer will buy in the next 7 days given their past purchase history.
They shared data from customers, transactions, and products and it was up to you to figure out how to use it.
The next time you have to solve a recommendation problem inside a company, you know which databases to look for and what to do with them to get a model working.
You Learn The Value Of Trustworthy Validation
“Trust your validation” is a phrase that is used often by the top competitors of the Kaggle community.
This doesn’t mean trusting any validation, but first creating a validation split that is trustworthy and not spending too much time “tuning” your model to climb the public leaderboard.
Climbing the leaderboard (in most cases) leads to overfitting and bad results on the private leaderboard, just like a bad validation scheme will lead to poor model performance in production.
Some competitions have terrible shake-ups between the public and the private leaderboard positions, which teaches a lesson you will never forget about how important it is to have a reliable validation split before deploying a model.
More than that, you will learn many different ways to validate your models that go beyond the usual random train/test split. Some Kagglers get very creative with it and then share it in the forums after the end of the competition.
A specific Kaggle tip that I learned from experienced competitors is to treat the public leaderboard as just another validation fold.
You Learn To Quickly Find Target Leakage
If your results look too good to be true, they probably are.
Leakage happens when information from the test set “leaks” into the training set through the features you are using. It’s information you would not have access to in production but is present in your historical data.
For example, imagine you are trying to predict tomorrow’s stock prices.
If you simply scale your data before splitting it into training and validation, your validation metrics will be much more optimistic than they should be.
This is because you are using information about the future in your training data.
Kaggle is a great place to learn this as it’s full of examples of leakage.
You will learn that when you find data leakage on Kaggle, you exploit it to win the competition, but when you see it outside of a competition, you fix it.
You Learn Reproducible Research Practices
When you win a competition, you have to submit your code along with a report explaining what you did and have a call with the sponsor.
This serves two purposes: showing you didn’t cheat and delivering valuable research.
It’s just one way that competitions teach you how to do reproducible research.
You have to organize all the mess of things you tried during the competition and make it generate predictions that would give you the same position on the leaderboard.
What if you never win?
Another way to practice it is by sharing work in a team during the competition.
In teams of experienced Kagglers, everyone works on their own, sharing little bits of code here and there.
Every team member has a copy of the full current best solution in his machine, so he can try adding new models to it.
This requires us to define shared validation splits and data, which is a big part of making a solution reproducible.
This is an excellent way to practice your research skills before having to do it in the “real world” because you can make all the mistakes you want without big consequences.
If you want to see how a well-organized final solution repository looks, check this one by Chenglong Chen.
You Develop Confidence
Every machine learning problem is the same but in different clothes.
You gain confidence that you can solve very difficult problems as you see yourself making progress in competitions that at first seemed out of reach.
I always had a feeling that the next competition would be the one I simply would not be able to do anything useful, but even in competitions where my solutions got crushed, I learned valuable lessons.
In fact, the competitions where I performed worse were the ones that taught me the most important things.
Expand Your Toolbox of Solutions
If you don’t know about a tool, you can’t use it.
The quality of your machine learning work is dependent on how many ideas, methods, and techniques you know for a given problem.
There is no way to know what will work before you try, but what if you only know 1 method?
The more candidate solutions you have, the better.
Kaggle competitions will force you to try many different techniques as you quickly iterate towards a solution.
This will help you learn many different ways to solve machine learning problems and give you a toolbox of methods to use in different cases.
For example, one tool I always find people don’t know about is Factorization Machines. Have you heard about this model?
It’s a great solution for very sparse, categorical data with millions of rows. It’s fast and implements a very smart way to model feature interactions.
If I didn’t compete on (or at least read about) Kaggle click prediction competitions, I would never know about this tool.
The Bad Parts of Kaggle
Spending Too Much Time On Kaggle Can Distort Your View Of Machine Learning
Machine learning in the industry is not about refreshing the leaderboard multiple times a day to see if you kept your position.
Still today I have trouble reminding myself that I don’t need to create the absolute best solution ever for a client. It needs to solve the problem and be maintainable.
At worst, I questioned myself: “Do I really know what I am doing if I can’t build a model that would win a competition?”
Impostor syndrome at its best!
Don’t spend so much time on Kaggle that you miss out on other important aspects of machine learning.
Kaggle should be on your skill development plan, but I’d also recommend you spend most of the time on end-to-end projects.
Start from understanding the business problem, do some data exploration to see if the data can help solve the problem, build and evaluate different models, and deploy it.
You can deploy models very easily today, be it a simple Gradio/Streamlit app, or a more complex pipeline on SageMaker and Vertex AI.
I find it much more satisfying to build something that is used by people than a model that only exists on my laptop.
Winning = Effort + Experience + Luck + Money
To win you have to test many ideas quickly. With ever-increasing dataset sizes, you will need to use cloud services to get bigger and faster machines. This will cost you real money.
Write it off as education costs, but be mindful of it. A few years ago a friend spent about 5k USD on AWS because of a misconfigured spot price and got 4th place in a competition. Only the top 3 spots got any prize money. Ouch!
The higher you go on the leaderboard, the more you have to rely on luck. The difference in scores between the top spots is so tiny that small random fluctuations in the data or your code can make a big difference.
And it’s not simply noise, but the luck of starting on the right path.
Every time I won a prize in any competition, it seemed to me as though every idea I tried improved my score. In other cases, almost everything I attempted failed right from the start.
While reading the solutions for the recent H&M Fashion Recommendation competitions I found at least 2 top teams that said Catboost was their best model and 2 top teams that said it was their worst.
Same data, two different development journeys, two different outcomes.
To win you have to not only create a good machine learning solution but spend a lot of time trying different competition-specific tricks.
A simple example is using your full dataset to scale features or encode categories, instead of only the training part.
In the Telstra competition (which I won), I spent a lot of time encoding the data leakage in different ways so I couldensemble everything and win.
On the Tube Pricing competition (which my team won), we spent a lot of time exploiting the Tube ID data leakage and creating ensembles with every available machine learning library you can think of.
You can find competitions where the winners went almost row by row looking for exploitable patterns that would translate to the private leaderboard because of some data processing mistake.
So if you decide to compete to win, know that you will spend a lot of time on things that are wrong in practice, but are necessary to win due to the nature of the data in competitions.
I recommend you have a goal outside of winning, like trying all types of categorical encoders or trying all tree-ensemble methods. This way you can take something away with you when the competition ends.
I once wanted to learn more about feature engineering, so I set a goal to only use “single models” (it could be a tree ensemble like XGBoost, but not a traditional Kaggle ensemble).
Besides being useful to know how to create strong single models in practice, every winning ensemble has a very strong single model that is complemented by other models.
In the Tube Pricing competition, my best single model was good enough to get 10th place.
Kaggle Data Is Static
In a competition, the data is static. You have to train a model that works well on a specific set of data.
This is different from the real world, where data changes all the time and you have to continuously update your models.
This is changing as some trading-related competitions already have an evolving leaderboard that requires you to write code that will run multiple times for months with new data.
All this while constrained by the computing resources available on Kaggle Kernels.
So… Worth It Or Not?
Kaggle is neither useless nor a silver bullet.
In general, be careful with people that say Kaggle is the only thing that matters and those that say it’s useless.
Most of the criticism is based on the expectation that Kaggle can teach you everything. But nothing can really teach you everything. Use Kaggle for what it’s good for.
I think every data scientist can benefit from trying to seriously compete in at least one challenge.
Besides the obvious technical learnings, you learn useful psychological skills like:
You learn to be resourceful. Instead of always asking someone for a solution to a problem you have to solve, you have to go and find a solution yourself.
You learn to be creative. If you want to improve your solution, you have to come up with original ideas that are not immediately obvious.
You learn to work under pressure. In a competition, every minute counts, and if you want to win you need to be able to deliver results quickly.
You learn how to handle frustration. You will probably spend more time than you expect trying different things that don’t work.
Kaggle is a tool, like many others, and it’s up to you to decide how to use it.
For me, Kaggle was worth a lot! I even got this cool hoodie!