The future of advertising attribution is modeled, predicted, estimated, or whatever other word you want.
One of the coolest tools (although still under early development) we have to model the impact of advertising campaigns on revenue is LightweightMMM, an implementation of bayesian marketing mix models developed by Google.
I talked about using this tool with my course sales data and really liked the results. I was surprised by the number of people that are trying to solve the same problem in their companies.
In this article, I will show how to use this tool to build a marketing mix model and find which channels are driving the best ROI for your advertising campaigns.
Preparing The Data
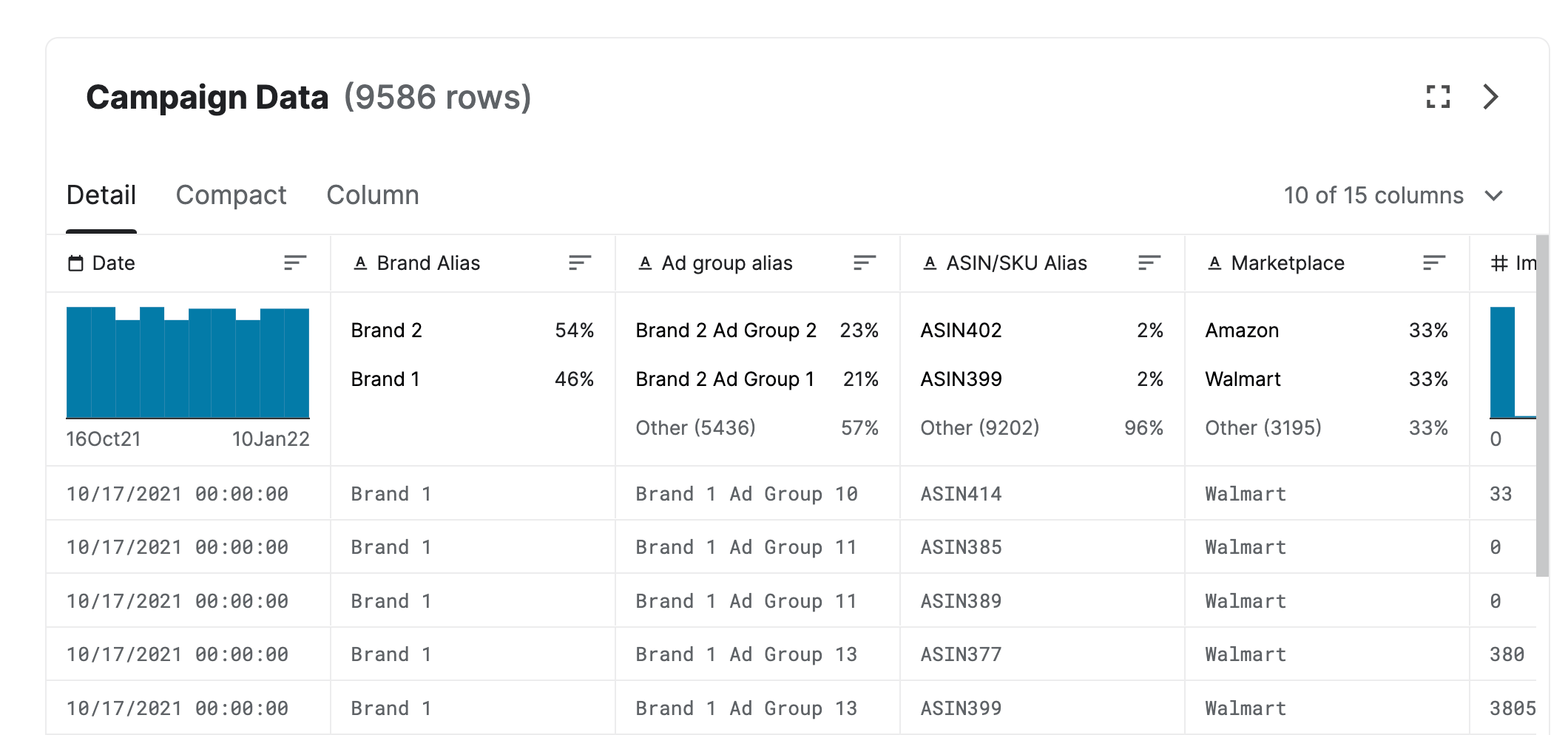
Instead of using my data, which has very specific patterns due to my niche, I found a cool dataset on Kaggle that has information about different ad groups that were set for brands in a few marketplaces like Walmart.

If you have never run an online ads campaign, they are usually organized by Campaign, Ad Group (or Ad Set), and Ads.
A campaign can have many ad groups that target different groups of people. For example, one ad group can be for people that subscribed to your e-mail list, another for people that visited sites about Python.
Then, inside each ad group, you have the ads that people in that group will see. You can have many ads, with different messages and formats (video vs image).
You never really know which campaign or ad group will be the best before running. It’s normal to launch multiple ad groups and after a few days turn off the ones that are not reaching your goals (like paying too much for someone to install an app).
The problem is that without attribution you don’t know which ad groups to turn off and which to allocate more budget.
With this data and a marketing mix model like LightweightMMM, we can take the data from the ad groups and correlate it to the marketing goal (revenue, installs, leads, etc) and proceed with our optimization (turning off stuff).
To do this, I preprocessed the media data into a format where each row corresponded to a day and each column was the number of impressions for an ad group.
!pip install --upgrade pip
!pip install --upgrade git+https://github.com/google/lightweight_mmm.git
import pandas as pd
from lightweight_mmm import preprocessing, lightweight_mmm, plot, optimize_media
import jax.numpy as jnp
from sklearn.metrics import mean_absolute_percentage_error
data = pd.read_excel("/content/Sr Advertising Analyst Work Sample (1).xlsx")
agg_data = data.groupby(["Date", "Ad group alias"])[["Impressions","Spend", "Sales",]].sum()
agg_data = agg_data.drop(["Brand 1 Ad Group 12"], axis=0, level=1) # zero cost train
media_data_raw = agg_data['Impressions'].unstack().fillna(0)
costs_raw = agg_data['Spend'].unstack()
sales_raw = agg_data['Sales'].reset_index().groupby("Date").sum()
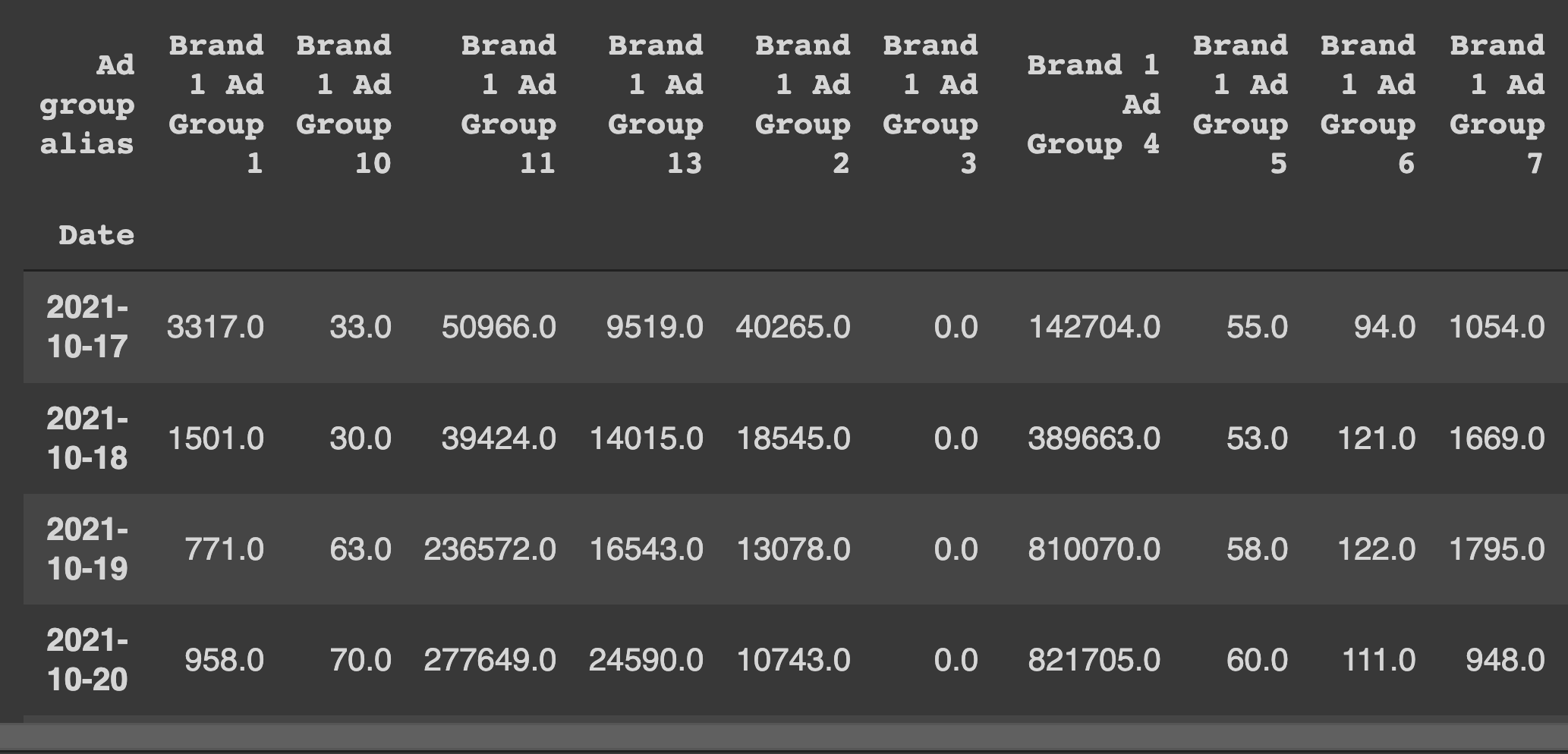
Impressions are how many times someone saw at least 50% of an ad. It can be the same person seeing it multiple times.
This is the recommended input data in most of the materials I studied. Probably because it’s a reliable measurement of the campaign delivery.
LightweightMMM uses the spend on a media channel (ad group, in our case) as a prior for the coefficient distribution, so we need to sum the spend for each channel too.
The last thing we need is the target. In our case, it’s the dollar amount of sales each day.
To find how good our model is, I used a simple validation split by time.
I selected the last 28 days as validation, even though they span Christmas time which can break things because our model will not have data from the previous Christmas to understand it’s a high purchase time.
split_point = pd.Timestamp("2021-12-15") # 28 days to end of data
media_data_train = media_data_raw.loc[:split_point - pd.Timedelta(1,'D')]
media_data_test = media_data_raw.loc[split_point:]
target_train = sales_raw.loc[:split_point - pd.Timedelta(1,'D')]
target_test = sales_raw.loc[split_point:]
costs_train = costs_raw.loc[:split_point - pd.Timedelta(1,'D')].sum(axis=0).loc[media_data_train.columns]
Let’s create some simulated organic data so we can see how to take it into account in the model.
organic_raw = pd.DataFrame({'organic_search': 0, 'organic_social': 0}, index=media_data_raw.index)
organic_raw['organic_search'] = sales_raw.values/10 + np.random.random_integers(10000, 100000, organic_raw.shape[0])
organic_raw['organic_social'] = sales_raw.values/10 + np.random.random_integers(10000, 100000, organic_raw.shape[0])
Using organic data as extra features can give you a more accurate view of your paid media effects.
Scaling The Data
LightweightMMM comes with simple-to-use scaler objects. I just followed what was recommended on the original documentation.
This can change if you have a lot of zeros in your data. Then they recommend you scale using only the non-zero values.
We need to scale everything: media data, costs, and the target. Each with a different scaler as usual.
This is important both to get a correct media effect estimate and to help the optimizer when it’s taking steps to find the right coefficients for the model.
split_point = pd.Timestamp("2021-12-15") # 28 days to end of data
media_data_train = media_data_raw.loc[:split_point - pd.Timedelta(1,'D')]
media_data_test = media_data_raw.loc[split_point:]
organic_data_train = organic_raw.loc[:split_point - pd.Timedelta(1,'D')]
organic_data_test = organic_raw.loc[split_point:]
target_train = sales_raw.loc[:split_point - pd.Timedelta(1,'D')]
target_test = sales_raw.loc[split_point:]
costs_train = costs_raw.loc[:split_point - pd.Timedelta(1,'D')].sum(axis=0).loc[media_data_train.columns]
media_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
organic_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
target_scaler = preprocessing.CustomScaler(
divide_operation=jnp.mean)
cost_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
media_data_train_scaled = media_scaler.fit_transform(media_data_train.values)
organic_data_train_scaled = organic_scaler.fit_transform(organic_data_train.values)
target_train_scaled = target_scaler.fit_transform(target_train.values.squeeze())
costs_scaled = cost_scaler.fit_transform(costs_train.values)
media_data_test_scaled = media_scaler.transform(media_data_test.values)
organic_data_test_scaled = organic_scaler.transform(organic_data_test.values)
media_names = media_data_raw.columns
Make sure you “squeeze” the target array, as using it with more than a single dimension will raise errors when plotting the results!
Finding The Right Hyper-Parameters
I care much more about out-of-sample error than in-sample, so I created a simple loop to do a tiny grid search to find the best value for two parameters: the adstock transformation and degrees of seasonality.
Based on my previous experiment, these are the two hyperparameters that make the most difference for this model.
I am completely against grid search for complex machine learning models that have more than 3 hyperparameters. Here each iteration takes 2 minutes and it’s only 9 evaluations, so we can afford it.
The evaluation metric is Mean Absolute Percentage Error (MAPE). It’s easy to interpret and usually a good one for models that forecast sales, like this one.
We can train using GPU or CPU. Every time I tried GPU on this or another dataset, it was much slower than CPU. So I just used CPU.
adstock_models = ["adstock", "hill_adstock", "carryover"]
degrees_season = [1,2,3]
adstock_models = ["hill_adstock"]
degrees_season = [1]
for model_name in adstock_models:
for degrees in degrees_season:
mmm = lightweight_mmm.LightweightMMM(model_name=model_name)
mmm.fit(media=media_data_train_scaled,
media_prior=costs_scaled,
target=target_train_scaled,
extra_features=organic_data_train_scaled,
number_warmup=1000,
number_samples=1000,
number_chains=1,
degrees_seasonality=degrees,
weekday_seasonality=True,
seasonality_frequency=365,
seed=1)
prediction = mmm.predict(
media=media_data_test_scaled,
extra_features=organic_data_test_scaled,
target_scaler=target_scaler)
p = prediction.mean(axis=0)
mape = mean_absolute_percentage_error(target_test.values, p)
print(f"model_name={model_name} degrees={degrees} MAPE={mape} samples={p[:3]}")
The predict method outputs the samples for each chain. To get a point estimate, we take the mean of the samples.
This model can be used with weekly data too, so to use it with daily data we need to use the weekday_seasonality parameter and adjust the seasonality_frequency parameter to capture the seasonality effects correctly.
Retraining LightweightMMM
After finding the best combination of hyperparameters we retrain the model, now using all the data.
Just like in the other model, carryover adstock and seasonality degrees = 1 was the best combination. But it takes 20+ minutes to run on Colab, so I settled for hill_adstock which is not much worse but runs in 2 minutes.
Online ads campaign data changes very quickly, so I would recommend retraining your model daily to always be working with the freshest patterns.
One additional experiment I would do if I had more data would be to find the best window size to train. For example: is it better if I use the last 3, 6, or 12 months of data to train my model?
There is no way of knowing without trying and seeing which gives you the best error. Just like I explained in the zero-inflated marketing mix model article.
costs = costs_raw.sum(axis=0).loc[media_names]
media_scaler2 = preprocessing.CustomScaler(divide_operation=jnp.mean)
organic_scaler2 = preprocessing.CustomScaler(divide_operation=jnp.mean)
target_scaler2 = preprocessing.CustomScaler(
divide_operation=jnp.mean)
cost_scaler2 = preprocessing.CustomScaler(divide_operation=jnp.mean)
media_data_scaled = media_scaler2.fit_transform(media_data_raw.values)
organic_data_scaled = organic_scaler2.fit_transform(organic_raw.values)
target_scaled = target_scaler2.fit_transform(sales_raw.values)
costs_scaled2 = cost_scaler2.fit_transform(costs.values)
media_names = media_data_raw.columns
mmm = lightweight_mmm.LightweightMMM(model_name="hill_adstock")
mmm.fit(media=media_data_scaled,
media_prior=costs_scaled2,
extra_features=organic_data_scaled,
target=target_scaled,
number_warmup=1000,
number_samples=1000,
number_chains=1,
degrees_seasonality=1,
weekday_seasonality=True,
seasonality_frequency=365,
seed=1)
Plotting LightweightMMM
LightweightMMM offers a multitude of plots that you can add to reports and presentations.
The two I like most are the media effects and the ROI plots.
The media effects plot shows an estimate of the coefficients for each media channel. High numbers mean the channel influenced the revenue more.
The x-axis is the estimated coefficient, the y-axis can be seen as how confident the model is that the x-axis value is the right value for the media effect.
plot.plot_media_channel_posteriors(media_mix_model=mmm, channel_names=media_names)
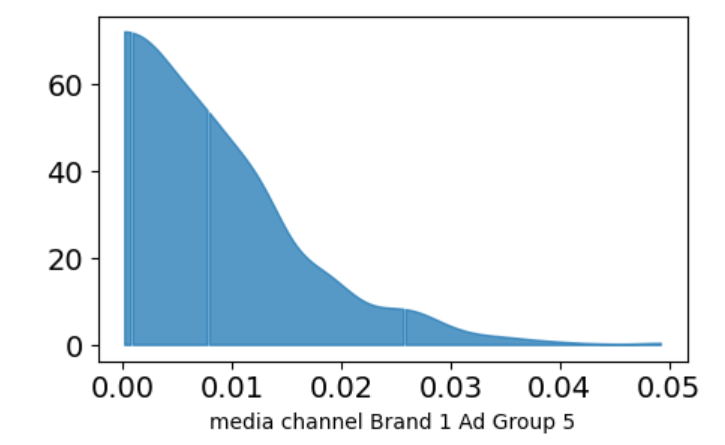
In the example above, the model thinks the effect for this channel is likely zero, but it’s not completely confident, so it extends its confidence to an area mostly between 0 and 0.02.
But only knowing the effect is limited, as a channel can be very effective but very expensive. So we have the ROI plot.
This plot takes into account not only the media effect but how much it costs to get this effect. The rule of thumb would be to allocate more budget to high ROI channels and less to low ROI ones.
This is not always possible, as a channel can have very good ROI but not be scalable.
Retargeting is an example: it’s very easy to get a good ROI when advertising for people that already know your product, but it’s a very limited group.
plot.plot_bars_media_metrics(metric=roi_hat, channel_names=media_names)
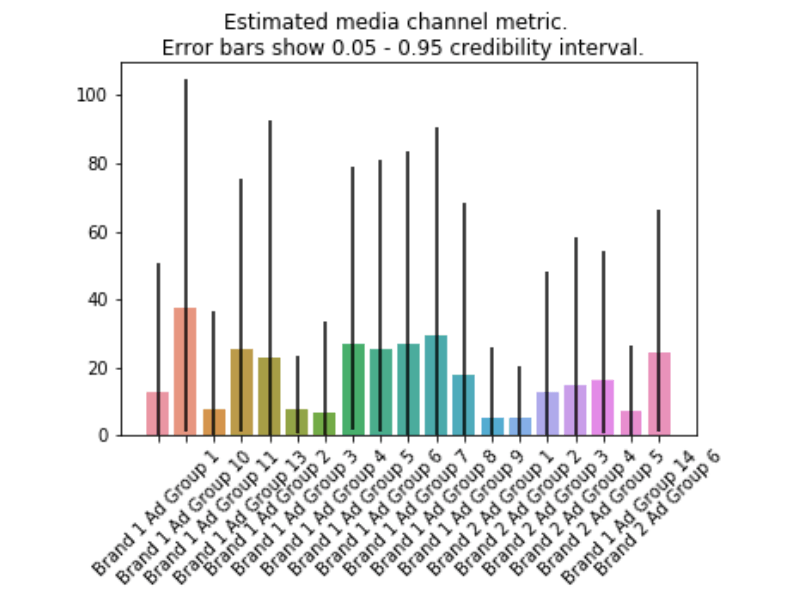
In practice, I used it as additional information to turn off ad groups and audiences that weren’t performing.
An additional tip: to run the plots in Colab, we need to install matplotlib version 3.1.3:
!pip uninstall -y matplotlib
!pip install matplotlib==3.1.3
LightweightMMM Budget Optimizer
The library offers a budget optimizer. It’s still not very clear to me how to use this tool. It takes a long time but can give you exact numbers to allocate to channels.
prices = costs / media_data_raw.sum(axis=0)
budget = 1 # your budget here
solution = optimize_media.find_optimal_budgets(
n_time_periods=10,
media_mix_model=mmm,
extra_features=organic_data_scaled[-10:, :],
budget=budget,
prices=prices.values)
prices is an array with the cost per impression for each media channel. I just took the historical cost.
The optimizer returns a tuple with 3 items. The third item (solution[3]) is the budget allocation.
As the ad buyer, I feel more comfortable taking the results of the model as guidance than using the exact numbers suggested by the optimizer.
Note that for this to work well, you would need to specify the organic impressions you expect to have in the future optimization period.
One way to do it is by simply considering the future will be like the most recent past (use the last N time periods of organic data as extra features).
As always, double-check your assumptions to make sure they are not too optimistic.
Expanding the Data with Geos
Since the last time I used the model, the developers added the option to use data at a more granular level, which is extremely valuable for these models.
The example in the documentation talks about using state-level data instead of aggregating at a national level when modeling ads in a large country like the United States.
This allows us to have more rows and get more accurate coefficients in our model.
Here we have data from 3 different marketplaces, so I wanted to see if treating each one as a different “geo” worked too.
This can be done by adding a dimension to the original data. So our input array will have dimensions (days, channels, geos).
agg_data = data.groupby(["Date", "Ad group alias", "Marketplace"])[["Impressions","Spend", "Sales",]].sum()
agg_data = agg_data.drop(["Brand 1 Ad Group 12"], axis=0, level=1) # zero cost train
media_data_raw_ = agg_data['Impressions'].unstack(level=1).fillna(1) # scaler goes crazy if fillna = 0 because of division by zero
sales_raw_ = agg_data['Sales'].reset_index().groupby(["Date", "Marketplace"]).sum()
costs_raw = data.groupby(["Date", "Ad group alias"])[["Spend"]].sum().drop(["Brand 1 Ad Group 12"], axis=0, level=1).unstack()
media_concat = list()
sales_concat = list()
for marketplace in ["Amazon", "Ebay", "Walmart"]:
df_ = media_data_raw_.loc[(media_data_raw_.index.get_level_values(0), marketplace), :].values
df_ = np.expand_dims(df_, 2)
media_concat.append(df_)
sdf_ = sales_raw_.loc[(sales_raw_.index.get_level_values(0), marketplace), :].values
#sdf_ = np.expand_dims(sdf_, 1)
sales_concat.append(sdf_)
media_data_raw = np.concatenate(media_concat, axis=2)
sales_raw = np.concatenate(sales_concat, axis=1)
split_point = -28
media_data_train = media_data_raw[:split_point, :, :]
media_data_test = media_data_raw[split_point:, :, :]
target_train = sales_raw[:split_point, :]
target_test = sales_raw[split_point:, :]
media_names = media_data_raw_.columns
costs_train = costs_raw.iloc[:split_point].sum(axis=0)
media_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
target_scaler = preprocessing.CustomScaler(
divide_operation=jnp.mean)
cost_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
media_data_train_scaled = media_scaler.fit_transform(media_data_train)
target_train_scaled = target_scaler.fit_transform(target_train.values.squeeze())
costs_scaled = cost_scaler.fit_transform(costs_train.values)
media_data_test_scaled = media_scaler.transform(media_data_test)
I had to fill the NaNs with 1 impression in the input data for the scaler and model to work. This should not throw off the model as we have many more legitimate impressions than NaNs.
The rest of the code is basically the same, but now we get a prediction for each day and geo instead of the aggregated target.
MAPE was slightly better as expected.
There are many ways we can slice this data to get more rows, but this is a topic for another article.
Extra Features
One capability I didn’t use here but can be very useful is that you can add extra features to your model beyond organic impressions data.
Suppose you ran a promotion for a week. You can create extra features indicating the days of the promotion so the model can better capture its effect.
LightweightMMM Is Promising
I really like this project and think it has a very bright future, this is why I decided to write a more in-depth, code-heavy, article about it.
At this moment I am not selling anything, so not buying ads, but when I run campaigns again I will definitely keep an updated model to help me optimize my budget.
I recently ran an experiment with it on Instagram and got a lesson about multicollinearity.
Happy modeling!