You have access to more data than you think – call transcripts, customer interviews, product reviews, competitor landing pages, blog content – there are hidden insights everywhere. You just have to be willing to sift through reams of unstructured data.
Thankfully ChatGPT is more than willing and never gets bored or takes a break. I work as a prompt engineer, and just wrote a prompt engineering book with O’Reilly, so when I needed to do qualitative analysis on customer interviews recently I decided to write a script for GPT-4o to do it for me. I’m sharing that script in this post, and explaining how it works so you can run it on your data too.
Make a copy of the QualitativeAnalysis.ipynb Google Colab file so you can follow along.
AI Qualitative Analysis Tutorial
LLMs, such as OpenAI’s GPT-4, have demonstrated their ability to analyze text and provide valuable insights. In this tutorial, we will explore how LLMs can be utilized for qualitative analysis and uncover hidden patterns and themes within textual data.
The dataset we’re using comes from a research paper with interviews with various teenagers on their interests. I couldn’t use the real dataset I was doing qualitative analysis of customer interviews on, but this is a good enough proxy to show you how it works.
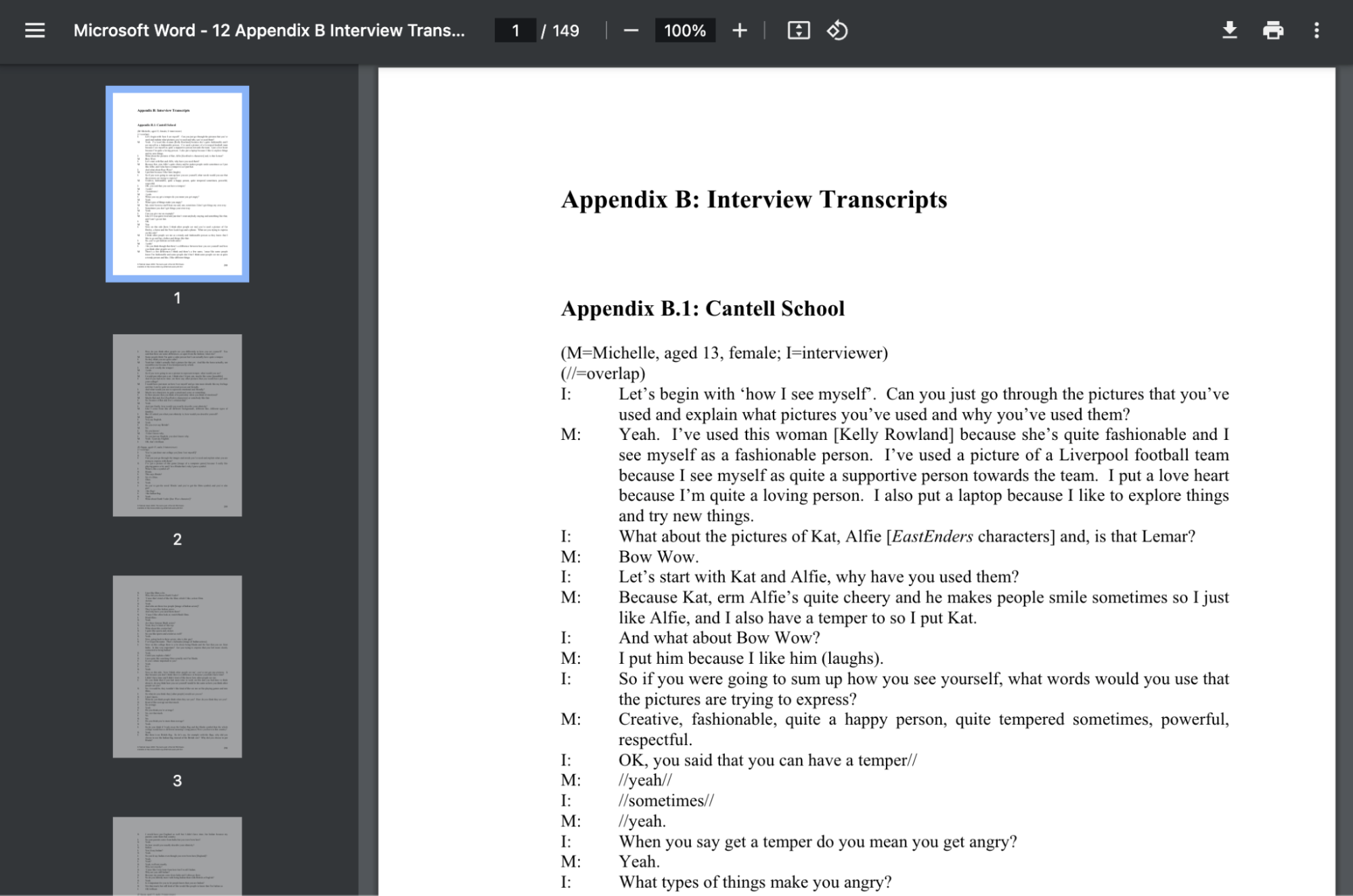
To get started with qualitative analysis using an LLM, you’ll need to install OpenAI and obtain an API key. Once you have your API key, you can begin the analysis process. The first step involves preparing your data. In the provided CSV file, the data consists of interview transcripts from the research paper. Each transcript is associated with a unique ID, which helps identify the relationships between labels and documents later.

Next, you create a prompt that guides the LLM in analyzing the data. This prompt highlights the objective of the analysis, which, in this case, is to identify thematic labels based on similarities and differences within the text samples. By running the analysis on a batch of data, you can obtain a list of labels associated with each document.
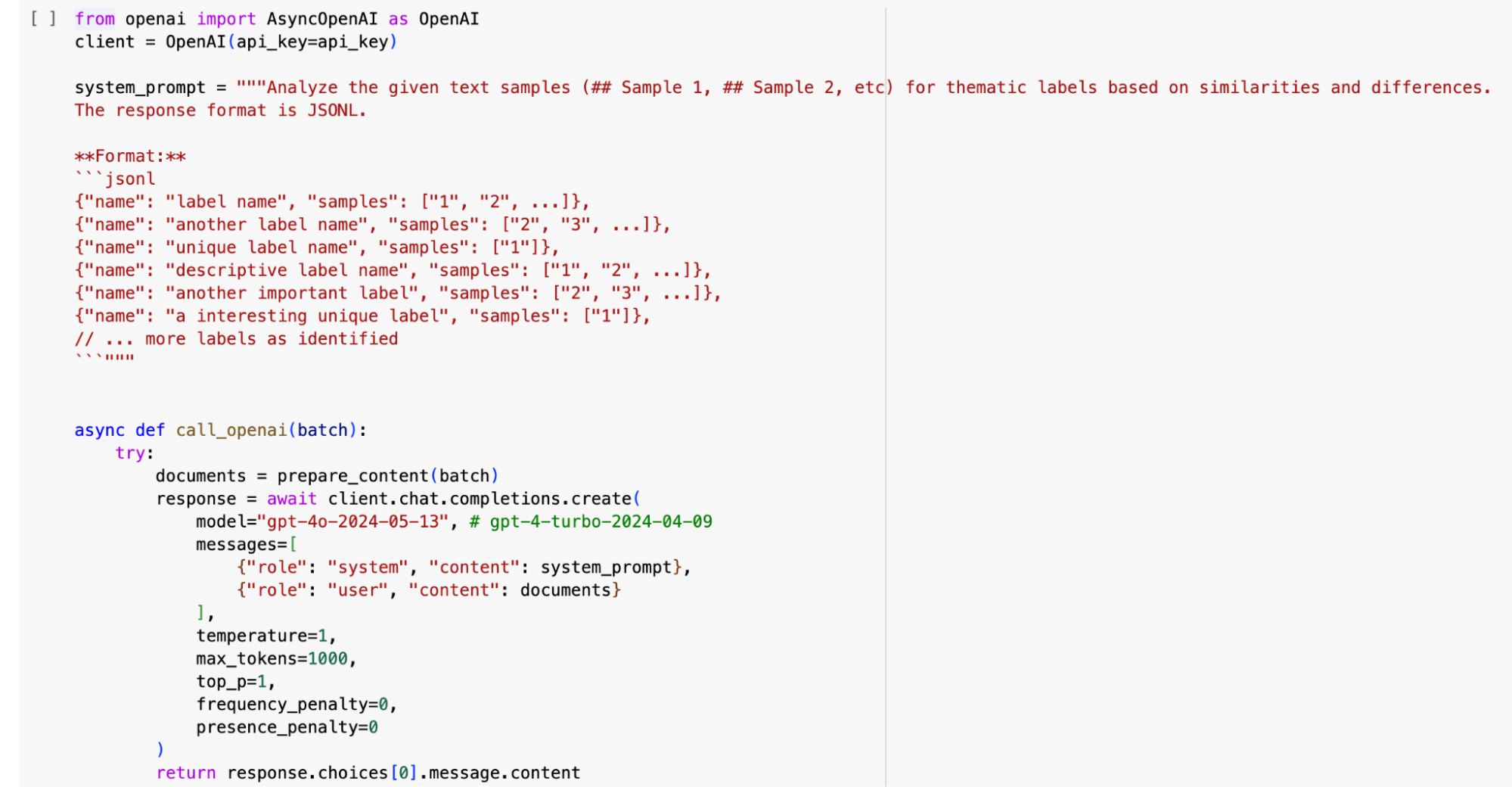
However, it’s often necessary to process a large volume of data that may not fit within a single prompt. To address this, a function is introduced in the transcript that shuffles and batches the data for efficient processing. This allows for simultaneous API calls, reducing the waiting time for results. The gathered results from all the batches are then combined into a list of labels for further analysis.
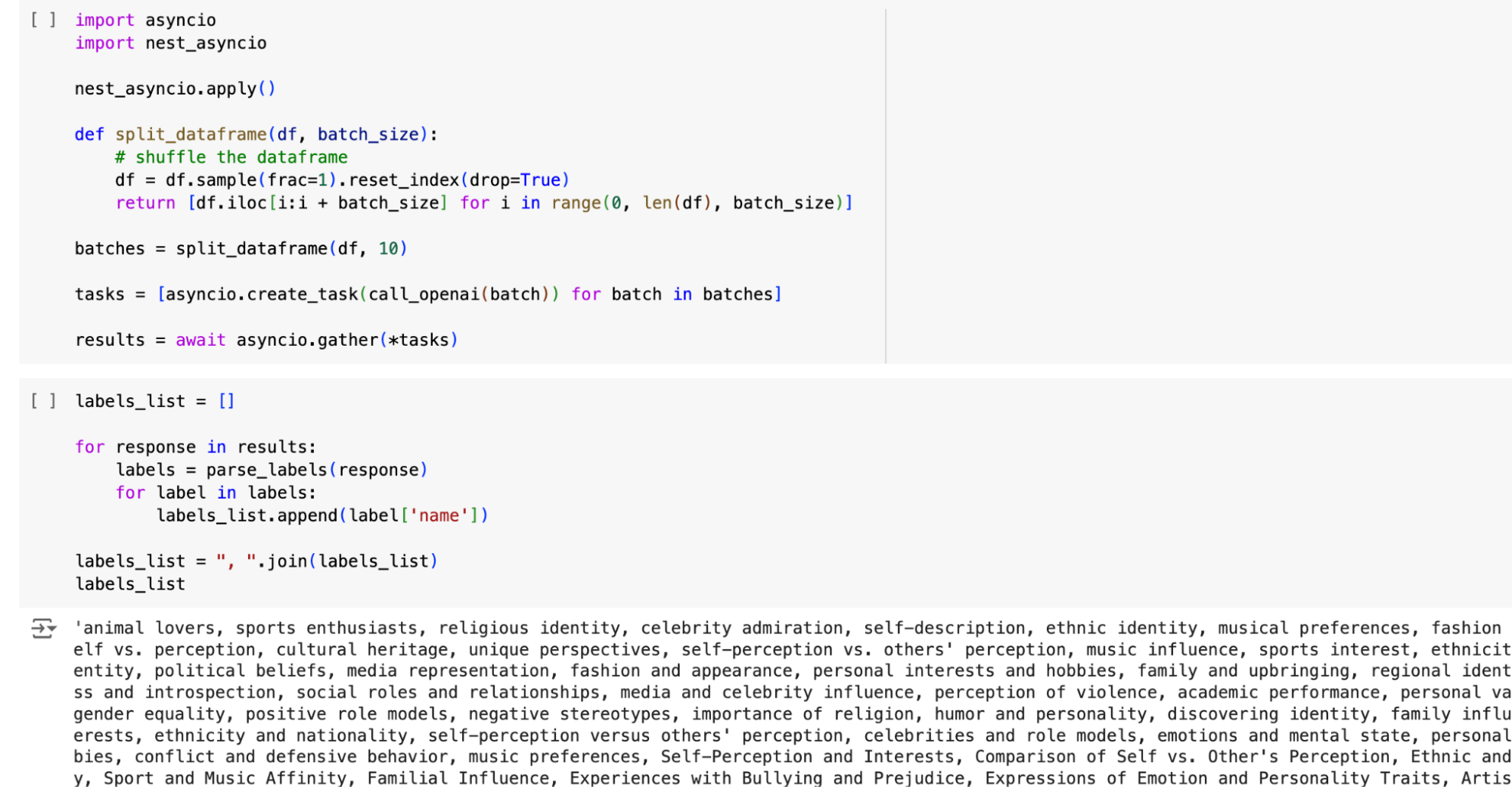
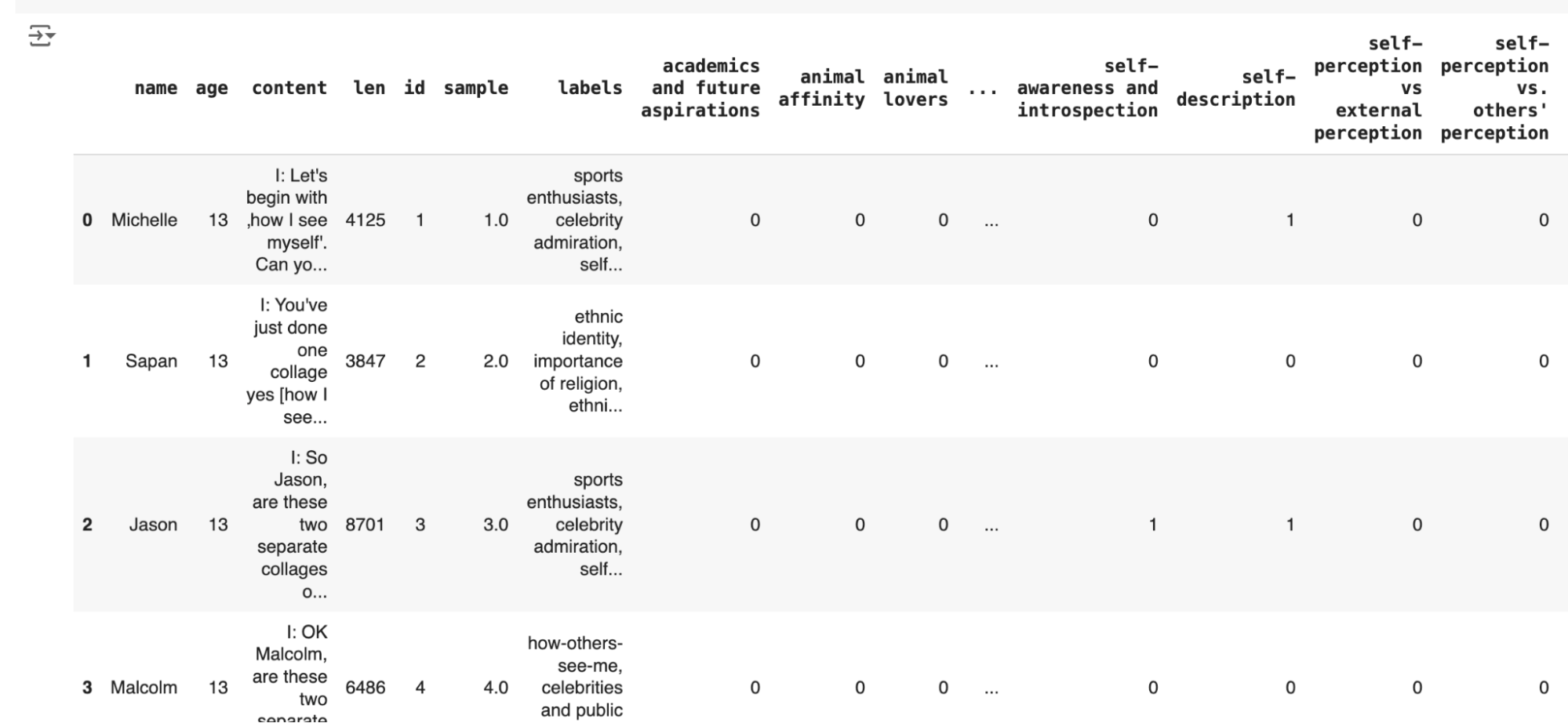
With a list of labels, you can then re-insert the labels into the prompt and run it against all batches of transcripts. This way you get a list of which documents the labels apply to across all documents and labels you found. If you were interested in specific labels that GPT-4o hasn’t found for you, you can always add them into this list before this step to identify where they apply also.

Once you have the results, you can examine the generated labels to identify common themes. Some labels may be unique to specific samples, while others may appear across multiple documents. This information helps in understanding the popularity of certain themes within the dataset. Additionally, there’s the possibility of refining the prompts to improve the quality of results, as some labels may not be as relevant or accurate.

The beauty of using LLMs for qualitative analysis lies in their ability to uncover hidden insights from unstructured text data. By leveraging the power of language models, you can quickly identify patterns in the data that a human would not be motivated enough to find. This can give you an edge against the competition and get a deep understanding of your audience.