
Gradient boosted decision trees (GBDTs) are the current state of the art on tabular data.
They are used in many Kaggle competitions and are the go-to model for many data scientists, as they tend to get better performance than neural networks while being easier and faster to train.
Neural networks, on the other hand, are the state of the art in many other tasks, such as image classification, natural language processing, and speech recognition.
Why is this? Why do neural networks perform so poorly on tabular data?
There is no definitive answer to this question, but there are many hypotheses.
The goal of this article is to be a living repository of hypotheses and experiments that I can come back to and refer people to when they ask me this question.
Feel free to reach out on LinkedIn if you have any suggestions to add to this article.
We Know How To Extract Good Features From Tabular Data
I find some of the hypotheses shared on this Reddit thread very interesting.
The main idea I got from it is that decision tree ensembles do better than neural networks on tabular data because feature engineering is clear and relevant information is already extracted.
This makes it easier for the model to learn the relationship between the features and the target.
It assumes that in images and text, for example, we don’t know how to extract good features, so we point to a likely structure (like convolutions in images) and let the model learn the features from an enormous amount of data.
This is a bit contradictory to an explanation presented below, related to the presence of uninformative features in tabular data.
Why Do Tree-based Models Still Outperform Deep Learning On Tabular Data?
This is the name of a very interesting paper that did a detailed analysis and came up with some of the best explanations I’ve seen so far.
The paper compares deep learning and tree-based models on 45 datasets of at most 50,000 samples.
These are the findings I found most interesting:
Decision Trees Do Feature Selection
Deep learning models are not robust to uninformative features, which are common in tabular data.
Uninformative features can introduce noise and reduce the signal-to-noise ratio, making it harder for deep learning models to learn meaningful patterns.
Tree-based models, on the other hand, can effectively ignore uninformative features by splitting on the most relevant ones.
It’s common for Kagglers to keep adding thousands and thousands of features to gradient boosted decision trees without seeing a real degradation in performance while clearly many of these features are uninformative (but we don’t have time to do selection during a competition).
There is a deeper finding about how the models deal with the rotation of the data differently which may contribute to this point.
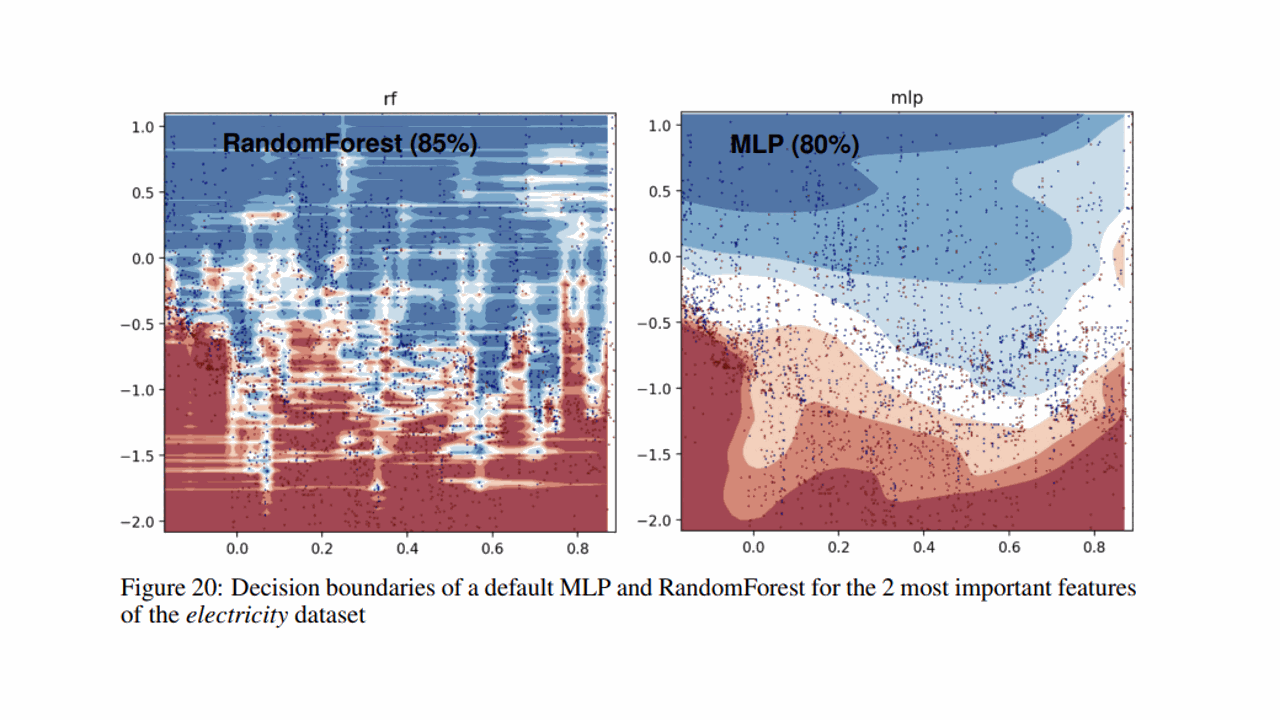
Decision Boundary Smoothness and Discontinuities
Deep learning models struggle to learn irregular functions, which are prevalent in tabular data.
In an example shown in the paper, the decision boundary found by the neural network is much smoother than the one found by the tree-based model.
Black-box Models Are Lower Risk
Evaluating the results of the M5 competition, the authors of “Forecasting With Trees” hypothesized that the reason why tree-based models are preferred in competitions is that they do well even with default parameters.
Not only that, but it allows competitors to focus on other aspects of the problem, such as feature engineering and ensembling.
Neural networks require more decisions (like feature scaling and architecture), which have a larger search space and are not as transferable.
For example, transfering a custom block in a neural network is not as guaranteed to improve a solution as transfering an engineered feature.
That said, from their experience at Amazon, they suggest that in an environment where you can spend more time on the problem, neural networks and even modifications to the off-the-shelf traditional models are worth exploring.
When Do Deep Learning Models Outperform Tree-based Models?
Large Amount Of Data
Talking with colleagues, reading papers, and watching use cases in the industry, deep learning seems to perform well (with enough research time and patience) in large tabular datasets.
Amazon research is coming up with deep learning solutions for sales forecasting, a problem that is traditionally solved with gradient boosted decision trees and lots of feature engineering.
You can find many tutorials about multiple time series forecasting with these types of models on this site.
Multimodal And Multi-Task Learning
When information beyond what can be stored in a table is available and relevant to the task, deep learning models seem to shine.
Meta recently launched a new ads targeting model that uses a multimodal and multi-task learning approach to compensate for the lack of data due to privacy mechanisms introduced by Apple on iOS and Safari that limit the amount of data that can be collected from users.
Previously, they used task-specific models to predict goals like the probability of a user clicking on an ad, installing an app, or making a purchase.
Online Learning
If you get hundreds of thousands of new samples every day, and your model benefits from learning from fresh data, training a new tree-based model every day may not be the best approach.
In this case, you may want to use a deep learning model that you can simply update with the new data like the team at Taboola presented on RecSys 2022.
Another great application of online learning with neural networks in a challenging industry environment was shown by Google for search ads CTR prediction.
Exploitable (Learnable) Structure
A pattern I see in cases where deep learning models do better than tree-based models, sometimes together with the factors above, is that there is a clear structure in the data that can be exploited by the model.
A classic case is time series forecasting, where we have a clear temporal structure that can be exploited.
Another case is when we have a graph structure, like in social recommender systems, where we can use graph neural networks to exploit the structure.
I like to think of neural network modeling as creating the scaffolding for the model to learn the structure of the data which would otherwise be extracted by feature engineering in tree-based models.
When Do Neural Nets Outperform Boosted Trees on Tabular Data?
UPDATED 2023-11-20: This is a new paper that compared neural networks and gradient boosted decision trees on many datasets.
At first, it seems like neural networks are equal to or better than GBDT, but when you look at the results more carefully, you see that the effect is valid only for specific subsets where GBDT has a hard time.
In general, if you have to pick one model, an implementation of GBDT is still your best bet, particularly CatBoost at the moment, according to papers and other practitioners.