You’ve probably heard about LSTMs, and might be curious about how they can help you with multiple time series forecasting.
As machine learning practitioners, we come across various forecasting tasks, and choosing the right model can sometimes be a challenge.
LSTMs have gained attention for their ability to handle long-term dependencies in sequential data, making them a promising choice for time series problems.
By the end of this tutorial, you’ll have a deeper understanding of LSTMs and be better prepared to use them effectively for multiple time series forecasting projects.
So, let’s begin this exciting journey together and start enhancing your forecasting skills!
We will use the NeuralForecast library.
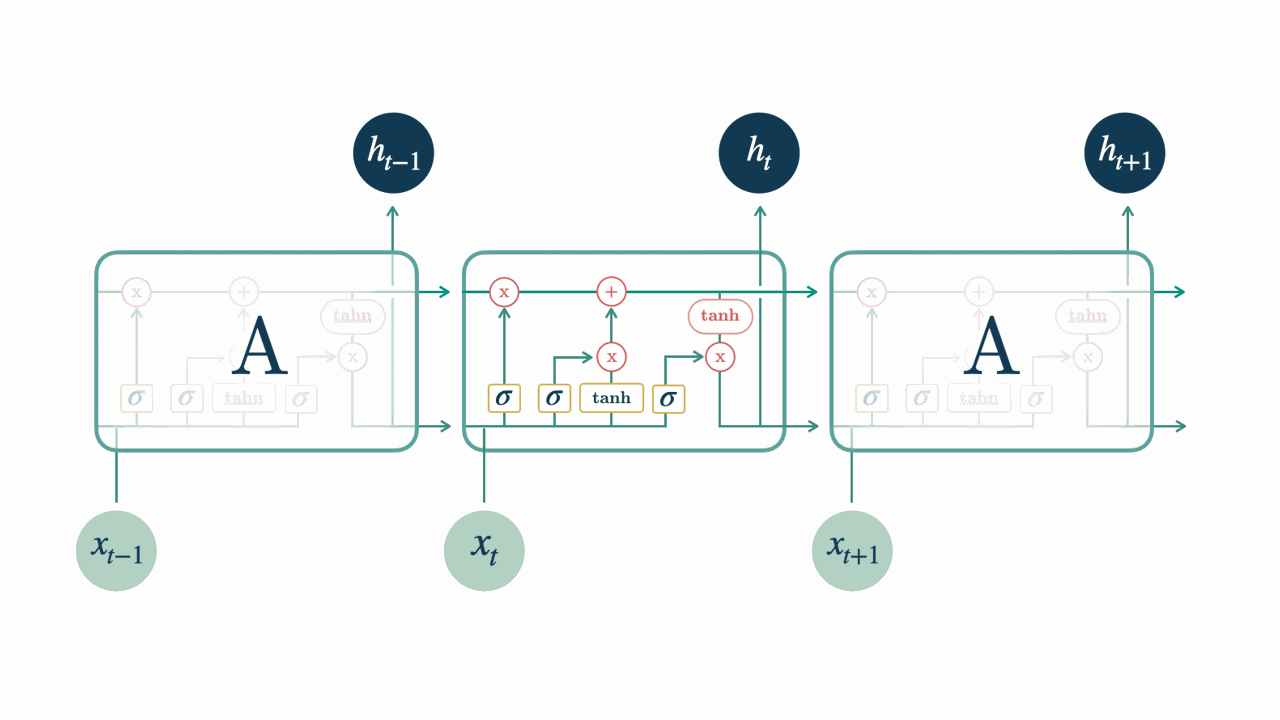
How Does an LSTM Work?
The LSTM cell will process one step of a sequence at a time, i.e. one observation of the time series at a time.
 source: https://nixtla.github.io/neuralforecast/models.lstm.html
source: https://nixtla.github.io/neuralforecast/models.lstm.html
While doing this, it maintains an internal state which contains information about the steps it has already seen.
This internal state, which can be thought of as the memory of the LSTM, is simply a matrix.
The input data for each point in a sequence contains the value at that time step and an internal (hidden) representation of the previous observations.
But this representation, although derived from it, is not the same as its internal state.
Therefore, we have three main components: the internal state, the hidden representation and the raw values of the time series.
The internal state and the hidden representation are set to zero at the start of the sequence.
The first step of the LSTM, when receiving data from a sequence, is to decide which information will be discarded from the current internal state.
It uses a “forget gate” to make this decision. This gate is a multiplication of the input data with a matrix, transformed by a sigmoid function.
In the second step it updates the internal state of the LSTM with new information.
It uses an “input gate”, similar to the forget gate, to define which information will be added to it.
In the third step it combines the information from the current internal state with the new information from the input series to create a new internal state.
In the fourth step, the LSTM uses an “output gate” to create the hidden representation to be passed to the next step based on the current internal state.
Then everything starts again using this hidden representation, the updated internal state and a new step of the time series.
When to Use an LSTM
LSTMs are very useful when you have any type of sequential data such as time series.
An example outside of time series is in natural language processing, as we can think of text as a sequence of words and process it using an LSTM.
Another example is video processing, since a video is just a sequence of images.
LSTMs can also be used for audio processing, since audio is also a series of data points.
So, if you have data that can be ordered in a sequence, it is worth trying an LSTM to model it.
Keep in mind that there are new architectures that don’t use recurrent connections and give similar results for sequential data, like N-BEATS.
How to Install NeuralForecast With and Without GPU Support
As NeuralForecast uses deep learning methods, if you have a GPU, it is important to have CUDA installed so that the models run faster.
To check if you have a GPU installed and correctly configured with PyTorch (backend library), run the code below:
import torch
print(torch.cuda.is_available())
This function returns True if you have a GPU installed and correctly configured, and False otherwise.
If you have a GPU but do not have PyTorch installed with it enabled, check the PyTorch official website for instructions on how to install the correct version.
I recommend that you install PyTorch first!!
The command I used to install PyTorch with GPU enabled was:
conda install pytorch pytorch-cuda=11.8 -c pytorch -c nvidia
If you don’t have a GPU, don’t worry, the library still works fine, it just won’t be as fast.
Installing it is very simple, just run the command below:
pip install neuralforecast
or if you use Anaconda:
conda install -c conda-forge neuralforecast
How To Prepare Time Series Data For The LSTM
Let’s use the very practical example of sales forecasting in this tutorial.
We will use real sales data from the Favorita store chain, from Ecuador.
We have sales data from 2013 to 2017 for multiple stores and product categories.
For this tutorial I will use only the data from one store and two product categories.
You can use as many categories, SKUs, stores, etc as you want.
import pandas as pd
import numpy as np
path = 'train.csv'
data = pd.read_csv(path, index_col='id', parse_dates=['date'])
data2 = data.loc[(data['store_nbr'] == 1) & (data['family'].isin(['MEATS', 'PERSONAL CARE'])), ['date', 'family', 'sales', 'onpromotion']]
This data doesn’t contain a record for December 25, so I just copied the sales from December 18 to December 25 to keep the weekly pattern.
dec25 = list()
for year in range(2013,2017):
for family in ['MEATS', 'PERSONAL CARE']:
dec18 = data2.loc[(data2['date'] == f'{year}-12-18') & (data2['family'] == family)]
dec25 += [{'date': pd.Timestamp(f'{year}-12-25'), 'family': family, 'sales': dec18['sales'].values[0], 'onpromotion': dec18['onpromotion'].values[0]}]
data2 = pd.concat([data2, pd.DataFrame(dec25)], ignore_index=True).sort_values('date')
The columns are:
date: date of the recordfamily: product categorysales: sales amountonpromotion: how many products of that category were on promotion on that day
weekday = pd.get_dummies(data2['date'].dt.weekday)
weekday.columns = ['weekday_' + str(i) for i in range(weekday.shape[1])]
data2 = pd.concat([data2, weekday], axis=1)
Let’s use the weekday as an additional feature.
It can be transformed as an ordinal or categorical variable, but here I will use the categorical approach which is more common.
In general, using additional information that is relevant to the problem can improve the model’s performance.
Date components like weekday, month, day of the month are important to capture seasonal patterns.
There are a ton of additional information that we could add, like temperature, rain, holidays, etc.
data2 = data2.rename(columns={'date': 'ds', 'sales': 'y', 'family': 'unique_id'})
This library expects the columns to be named in the following format:
ds: date of the recordy: target variable (sales amount)unique_id: unique identifier of the time series (product category)
unique_id should identify each time series you have.
If we had more than one store, we would have to add the store number along with the categories to unique_id.
An example would be unique_id = store_nbr + '_' + family.
This is the final version of our dataframe data2:
| ds | unique_id | y | onpromotion | weekday_0 | weekday_1 | weekday_2 | weekday_3 | weekday_4 | weekday_5 | weekday_6 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2013-01-01 00:00:00 | MEATS | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2013-01-01 00:00:00 | PERSONAL CARE | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2013-01-02 00:00:00 | MEATS | 369.101 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2013-01-02 00:00:00 | PERSONAL CARE | 194 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2013-01-03 00:00:00 | MEATS | 272.319 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
A row for each record containing the date, the time series ID (family in our example), the target value and columns for external variables (onpromotion).
Notice the time series records are stacked on top of each other.
Let’s split the data into train and validation sets.
How To Split Time Series Data For Validation
You should never use random or k-fold validation for time series.
That would cause data leakage, as you would be using future data to train your model.
In practice, you can’t take random samples from the future to train your model, so you can’t use them here.
To avoid this issue, we will use a simple time series split between past and future.
A career tip: knowing how to do time series validation correctly is a skill that will set you apart from many data scientists (even experienced ones!).
Our training set will be all the data between 2013 and 2016 and our validation set will be the first 3 months of 2017.
train = data2.loc[data2['ds'] < '2017-01-01']
valid = data2.loc[(data2['ds'] >= '2017-01-01') & (data2['ds'] < '2017-04-01')]
h = valid['ds'].nunique()
What Is The Architecture Of NeuralForecast’s LSTM?
This implementation uses an encoder and a decoder, a very successful architecture when dealing with sequential data.
The encoder will distill the input sequence into a compact representation, keeping the information that is important for the target we want to predict.
The decoder will receive these features (encoded representation) and make the predictions.
The encoder is an LSTM and the decoder is a feedforward neural network (MLP).
There are a few hyperparameters that are important to know before training the model.
context_size
This parameter controls how many steps in the past will be used to predict the next step.
By default it is 10, which means that the network will use the last 10 steps to predict the next one.
encoder_hidden_size
Controls the number of units (neurons) of the encoder’s internal representation (hidden layer).
The larger it is, the more capacity the network has to learn complex patterns, but also increases the risk of overfitting.
All layers of the LSTM will have the same number of units.
encoder_n_layers
Controls the number of layers in the encoder.
Just like the size of the internal representation, the larger the number of layers, the more capacity to learn complex patterns, but also more chances of overfitting.
decoder_hidden_size
Controls the number of units (neurons) of the decoder’s internal representations.
The decoder is a regular feed-forward neural network (MLP).
decoder_layers
Controls the number of layers in the MLP decoder. It’s 2 by default.
scaler_type
Neural networks are very sensitive to the scale of the input data, so it’s usually a good idea to scale it.
The library has three options for scaling the data:
None: no scalingstandard: standard scalingrobust: robust scaling
standard scales the data by subtracting the mean and dividing by the standard deviation.
robust does it by subtracting the median and dividing by the mean absolute deviation.
learning_rate
One of the most important hyperparameters for any neural network.
It controls the step size used by the optimization algorithm to update the network’s weights.
If it’s too large, the algorithm may diverge and never find a good solution.
If it’s too small, the algorithm may take a long time to converge.
max_steps
This argument controls the maximum number of training steps.
It determines how many times the optimization algorithm will update the network’s weights.
The lower the learning_rate, the more steps are necessary for convergence.
Solutions with a high number of steps and a low learning_rate take longer to train, but tend to be more stable and performant.
How To Train The LSTM In Python
from neuralforecast import NeuralForecast
from neuralforecast.models import LSTM
from neuralforecast.losses.pytorch import DistributionLoss
models = [LSTM(h=h,
loss=DistributionLoss(distribution='Normal', level=[90]),
max_steps=100,
encoder_n_layers=2,
encoder_hidden_size=200,
context_size=10,
decoder_hidden_size=200,
decoder_layers=2,
learning_rate=1e-3,
scaler_type='standard',
futr_exog_list=['onpromotion'])]
model = NeuralForecast(models=models, freq='D')
We need the NeuralForecast and LSTM classes to train the network.
NeuralForecast is an utility class to manage the internals of training the neural network.
LSTM is the class that implements the architecture we saw above.
First we create a list with the models we want to train, in this case only LSTM.
NeuralForecast was made to train multiple deep learning models at the same time, this is why we need to pass a list, even if it has only one model.
The LSTM class has many arguments, including the hyperparameters I explained above.
Beyond them, you need to know:
h: horizon, the number of steps into the future we want to predictloss: the loss function that will be used to optimize the weights of the networkfutr_exog_list: a list of the names of the external variables we want to use in the forecast
In this case I picked the DistributionLoss class, which implements the very successful loss function used in DeepAR.
You can play with the distribution and the confidence level to adjust the loss function to your needs.
Here I am using a normal distribution with a 90% confidence interval (5% on each side).
There are three types of external variables we can use with this implementation:
futr_exog_list: external variables that are available for the forecast horizon. In this examples, I am assuming we know the days in the future when we will run promotions.hist_exog_list: external variables that are available only for the historical data. For example, if we wanted to adjust for promotions during training, but didn’t know the days when we would have promotions in the future.stat_exog_list: If you have static external variables (for example, the store’s city), you can use this. It will automatically add the variables to the input for the forecast horizon.
Lastly, we pass the list of models to the NeuralForecast class and set the data frequency as D (daily).
model.fit(train)
p = model.predict(futr_df=valid).reset_index()
p = p.merge(valid[['ds','unique_id', 'y']], on=['ds', 'unique_id'], how='left')
We use the fit method to train the model, passing a DataFrame to futr_df with the additional columns for the forecast horizon.
If you didn’t use any external variables, you don’t need to pass anything.
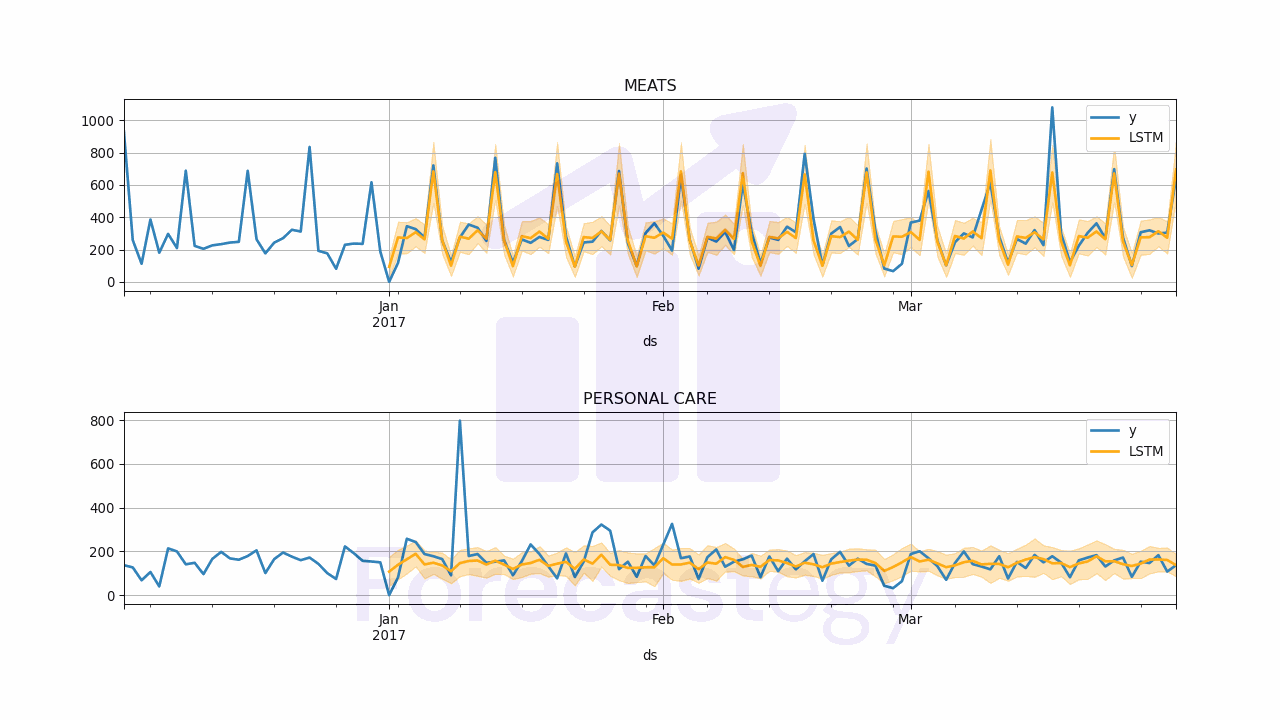
The predict method returns a DataFrame with the predictions for the horizon h, starting from one period after the last date in the training set.
In order to evaluate the performance of the model I merged the targets with the predictions.
This is what p looks like:
| unique_id | ds | LSTM | LSTM-median | LSTM-lo-90 | LSTM-hi-90 | y |
|---|---|---|---|---|---|---|
| MEATS | 2017-01-01 00:00:00 | 228.308 | 225.023 | -18.8352 | 472.047 | 0 |
| MEATS | 2017-01-02 00:00:00 | 317.114 | 315.692 | 62.218 | 567.722 | 116.724 |
| MEATS | 2017-01-03 00:00:00 | 319.258 | 315.637 | 56.932 | 590.75 | 344.583 |
| MEATS | 2017-01-04 00:00:00 | 311.593 | 303.065 | 55.9758 | 567.078 | 326.203 |
| MEATS | 2017-01-05 00:00:00 | 317.758 | 318.041 | 86.6034 | 568.66 | 274.205 |
unique_id: the time series ID of that rowds: the date corresponding to the predictionLSTM: the point forecast (mean of the predicted samples when usingDistributionLoss)LSTM-median: the median of the predicted samplesLSTM-lo-90: the 90% confidence interval lower boundLSTM-hi-90: the 90% confidence interval upper bound
How To Tune The LSTM Hyperparameters
If you feel overwhelmed by the number of hyperparameters, don’t worry, you are not alone.
I love to use Bayesian optimization to tune the hyperparameters of my models, and this can be done very easily with Optuna.
You can install Optuna with pip:
pip install optuna
Or with conda:
conda install -c conda-forge optuna
This is not an excuse to not understand the hyperparameters, but it can help you get started.
First, we need to define the objective function that will be optimized.
from sklearn.metrics import mean_absolute_error
import optuna
def objective(trial):
encoder_n_layers = trial.suggest_int('encoder_n_layers', 1, 3)
encoder_hidden_size = trial.suggest_categorical('encoder_hidden_size', [64, 128, 256])
decoder_layers = trial.suggest_int('decoder_layers', 1, 3)
decoder_hidden_size = trial.suggest_categorical('decoder_hidden_size', [64, 128, 256])
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-1)
context_size = trial.suggest_int('context_size', 1, 60)
scaler_type = trial.suggest_categorical('scaler_type', ['standard', 'robust'])
models = [LSTM(h=h,
loss=DistributionLoss(distribution='Normal', level=[90]),
max_steps=100,
encoder_n_layers=encoder_n_layers,
encoder_hidden_size=encoder_hidden_size,
context_size=context_size,
decoder_hidden_size=decoder_hidden_size,
decoder_layers=decoder_layers,
learning_rate=learning_rate,
scaler_type=scaler_type,
futr_exog_list=['onpromotion'])]
model = NeuralForecast(models=models, freq='D')
model.fit(train)
p = model.predict(futr_df=valid).reset_index()
p = p.merge(valid[['ds', 'unique_id', 'y']], on=['ds', 'unique_id'], how='left')
loss = mean_absolute_error(p['y'], p['LSTM'])
return loss
In this function, we suggest the possible values for each hyperparameter using trial.suggest_* methods.
For example, suggest_int will pick an integer between the two values passed as arguments, suggest_categorical will pick one of the values passed as a list.
The ranges you see above are the ones I found to work well in practice, so they are a good starting point.
I like to set the hidden_size to multiples of 2 because GPUs tend to work better with it.
I set the context_size to a maximum of 60 because I want it to consider at most 2 months (60 days), remember to adjust it according to the frequency of your data.
To demonstrate, I set the loss to be the mean absolute error, but you can use any metric you want.
This is not the same loss function that will be used to train the model, it’s just a metric to evaluate the performance of the model on the validation set.
Finally, run the Optuna optimization:
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=30)
We set the direction to minimize because we want to minimize the loss function.
If this was a “positive is better” metric, like coverage probability, we would set it to maximize.
In practice, I find that 20 to 30 trials are enough to find a good set of hyperparameters.
After the optimization finishes, you can get the best set of hyperparameters with:
study.best_params
And the best value of the loss function (corresponding to the best hyperparameters) with:
study.best_value
Frequently Asked Questions
How To Train The LSTM With Multiple SKUs?
The only change is that your unique_id column will be the SKU. You can use the rest of the code as is.