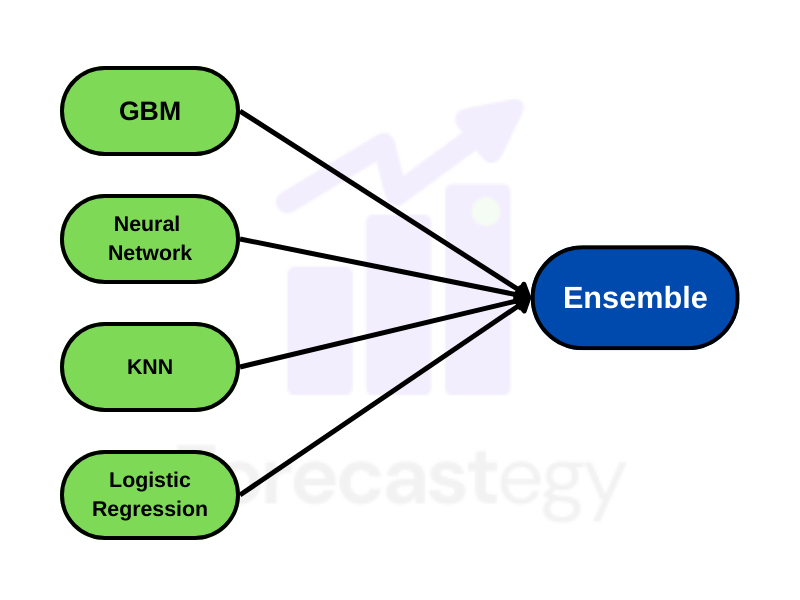
A lot of people find machine learning ensembles very interesting.
This is probably because they offer an “easy” way to improve the performance of machine learning solutions.
The place where you will see a lot of ensembles is Kaggle competitions, but you don’t need to be a Top Kaggler to know how to build a good ensemble for your project.
I have spent a lot of time building and thinking about ensembles and here I will tell you my “4-step ensemble framework”.
I tested this framework from simple average ensembles to multi-level stacking. I even used it to build the ensemble that won the Telstra competition, so it works! ;)
Let’s dive in!
What Makes a Good Machine Learning Ensemble?
Diversity and accuracy.
And I put diversity first on purpose.
Sometimes you have models with terrible accuracy that contribute well to an ensemble.
Although it’s not a consensus in the research literature, in practice the idea is to have uncorrelated models that perform well on the dataset.
This doesn’t mean the models need to be perfectly uncorrelated. Many of my best ensembles had models with a 0.9+ correlation between them.
Selecting models for an ensemble is just like selecting features in a forward fashion.
You start with the model that works best on your problem and keep adding models that improve the performance of your ensemble until you reach a point where adding more models doesn’t help (or harm) the final performance.
So the more models you can build, the better.
The real question that got me to develop my framework is: how to generate many diverse but accurate models?
An Aside: Are Ensembles Used Outside of Competitions?
Yes.
I have deployed ensembles, my friends have deployed ensembles, and big companies have deployed ensembles.
It’s not a competition trick. It’s a legitimate way to build better machine learning solutions.
The 4 Dimensions Of An Ensemble
Whenever I need to build an ensemble I think about 4 dimensions I can manipulate:
- Machine learning models/algorithms
- Features (Columns)
- Examples (Rows)
- Hyperparameters
These are in the order that worked best for me. E.g: combining different machine learning models tend to work better than combining the same model with different hyperparameters.
Let’s dive into each of these points:
Different Machine Learning Models and Algorithms
Just so we are on the same page. Following what I learned in the great Abu-Moustafa Caltech ML course, a machine learning model is like a blueprint and the algorithm is what you use to fill the blueprint according to your data.
A feed-forward neural network is a model. Gradient descent is an algorithm to train it. A decision tree is a model. Greedy search is an algorithm to train it.
The first thing I do when building an ensemble is try different models and algorithms.
One of the best combinations that almost always work for tabular data is training a gradient-boosted tree model (like XGBoost) and a neural network on the same dataset and averaging their predictions.
But you can expand it to any other class of models.
The four that I usually try are gradient-boosted trees, neural networks, linear/logistic regression, and K-nearest neighbors.
Combining these 4 types of models got me very good results inside and outside of competitions.
Each model will look at your data differently and make different predictions. And that’s exactly what you want in an ensemble!
You can go deeper into a model and train it using different algorithms. In neural networks, you can vary the optimizer, in gradient boosting you can try XGBoost, Catboost, and LightGBM.
The idea is to exhaust the types of models and algorithms you can build.
A great example was the Otto Competition 1st Place Solution where Giba and Stas used some exotic libraries to find more models to ensemble.
You will not use all the models at the end, but trying many of them will allow you to find the right combination.
And don’t forget to try changing the architecture of your neural networks.
Sometimes simply combining 1-layer, 2-layer and 3-layer neural networks already make a good ensemble.
If you are dealing with unstructured data, a straightforward way is to use the embeddings of or fine-tune different pre-trained models and combine their predictions.
Different Features (Columns)
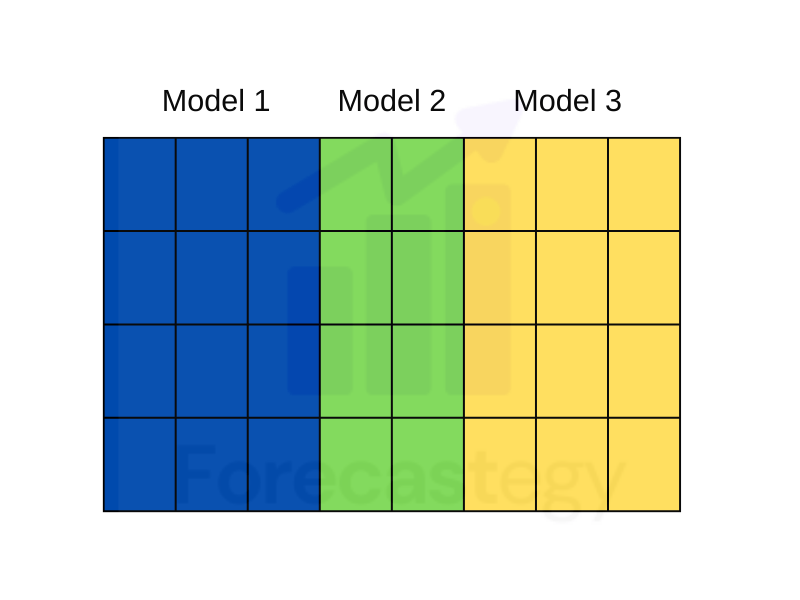
The second thing I vary is the feature set.
In most datasets, there are hundreds or thousands of features you can create. And some of them will be better than others at predicting your target variable.
When building ensembles you can try building models with different combinations of features and see if it improves your final score.
The way I like to do it is by trying different random combinations of features or groups of features and seeing what works best on the validation set (or cross-validation).
Let’s say you are building a recommender system where you have user and item features. Try building a model that only uses user features and another that uses only item features.
It will probably not be as good as a model with both feature sets, but it can capture a few patterns that the global model won’t be able to. It’s what makes the subset model bad on its own but good in an ensemble.
It may even overfit a bit to the specific constrained space it has, but you can think about it as having different “overfitted” specialists in a committee.
Let your ensembling weights/stacking decide who contributes what at the end.
Different Examples (Rows)
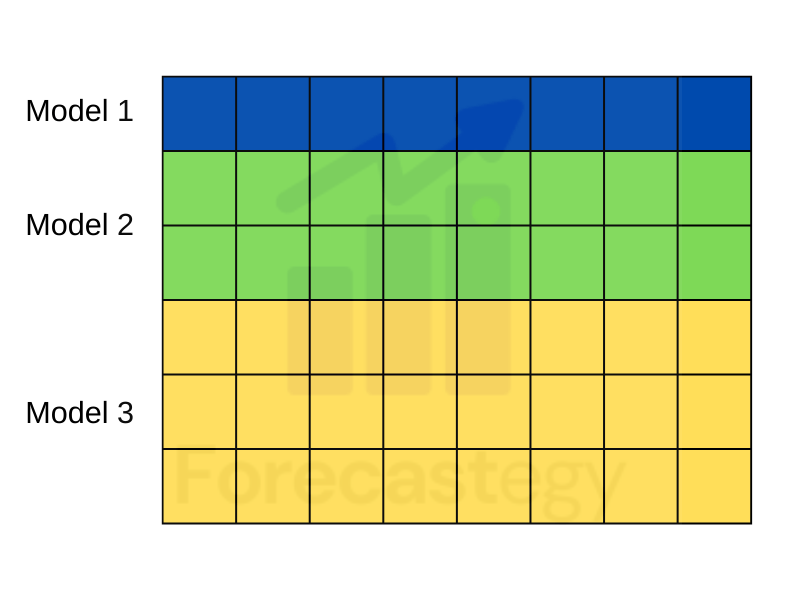
The third thing I vary is the subset of data used to train the model.
It can be a traditional way like bagging or even simply randomly selecting rows.
During the Tube Pricing competition, Josef Feigl wanted to ensemble different Regularized Greedy Forest models, so he created random 90% subsets of the original data and averaged the results.
It doesn’t need to be random. Let’s say you want to forecast sales for products in different categories.
You can have the global model trained on everything and then models created using only subsets of data of each category. Combine them and you will find gold!
The takeaway is to have models trained on different subsets of rows/examples.
Different Hyperparameters
The last thing I try is varying the hyperparameters of the model.
It can go from having gradient-boosting models with deep and shallow trees to having K-nearest neighbors with different numbers of neighbors.
I have seen Stas do it very well during the Two Sigma competition, but for me, it was never the best way to generate different models, this is why I leave it as the last tool.
A great example is Tim Scharf’s solution to one of the Walmart competitions.
He generated a ton of XGBoost models with random hyperparameters and bagging, then stacked everything to get the 3rd place.
Ensembling by changing hyperparameters works better when you have many hyperparameters to tune, so randomizing the regularization coefficient of a Ridge regression will not be as effective as randomizing the parameters of gradient-boosted trees.
Whenever you have a model that needs a random seed to work, try training the same model with different seeds.
It doesn’t matter if it’s a neural network or XGBoost, having different random seeds will create slightly different models and lead to better results when you average them.
It’s one of the easiest ways to get a better solution.
In my experience, overfitting neural networks a little bit (like letting it run for 1 epoch more than the optimal) and then averaging the predictions of models with different random seeds leads to better results.
And the more weights a neural network has, the more you will benefit from averaging different random seeds.
What To Do Next?
After you have a ton of models, building the ensemble becomes straightforward.
There are a lot of ways to combine the models, but you can start with a simple average and then progressively use more sophisticated methods like stacking.
Just treat each model prediction as a feature and run a forward feature selection process.
There is one interesting technique by Rich Caruana where instead of running a traditional weighted average optimizer (like scipy.minimize), he runs a forward selection with replacement.
The same model can be selected more than once, which allows for it to have a higher weight in the combination.
I like it because you don’t have to pre-select the models that will compose the ensemble. The weights and model selection are “learned” together.
Happy ensembling!