
Have you ever found yourself puzzled by the different options for categorical encoding in CatBoost?
With so many methods available, it can be quite a challenge to figure out which one is the best fit for your project.
In this tutorial, I will demystify the various encoding options.
By the end of this guide, you’ll be well-equipped to make an informed decision and handle categorical features in CatBoost like a pro!
How To Install CatBoost
Installing CatBoost is a straightforward process. You can use either pip or conda, two popular package managers for Python.
If you prefer to use pip, you can install CatBoost by running the following command in your terminal:
pip install catboost
Alternatively, if you’re using the Anaconda distribution of Python, you can use the conda package manager to install CatBoost.
Here’s the command you’d use:
conda install -c conda-forge catboost
In both cases, the command should download and install the CatBoost library, making it available for you to import in your Python scripts.
Categorical Variable Encoding In CatBoost
CatBoost has several encoding options to transform categorical variables into numerical values.
For the target encoding variants, CatBoost uses a neat trick to avoid overfitting.
It first shuffles the rows of the training dataset 4 times, then it calculates the target encoding sequentially for each level of each categorical feature and each permutation of the dataset.
It’s similar to leave-one-out encoding.
This guarantees that each permutation has a slightly different encoding for the levels, which helps prevent trees to overfit to the encoding.
After that, every time it needs to build a new tree (for each boosting iteration), it uses a different permutation of the dataset.
So you have double protection against overfitting: the encoding is different for each permutation, and the permutation is different for each tree.
Because the permutations are not extremely different from each other, the model can still learn from the encoding.
Let’s see the specific encoding variations that CatBoost supports.
One-Hot Encoding
For categorical features with less than 255 unique values, CatBoost uses a method called “One-Hot Encoding”.
This method creates a new binary column for each unique value in the categorical feature.
The value of the new feature is 1 if the original feature value matches the new feature’s value and 0 otherwise.
You can change the threshold for the number of unique values (255) by setting the one_hot_max_size parameter when you start training your model.
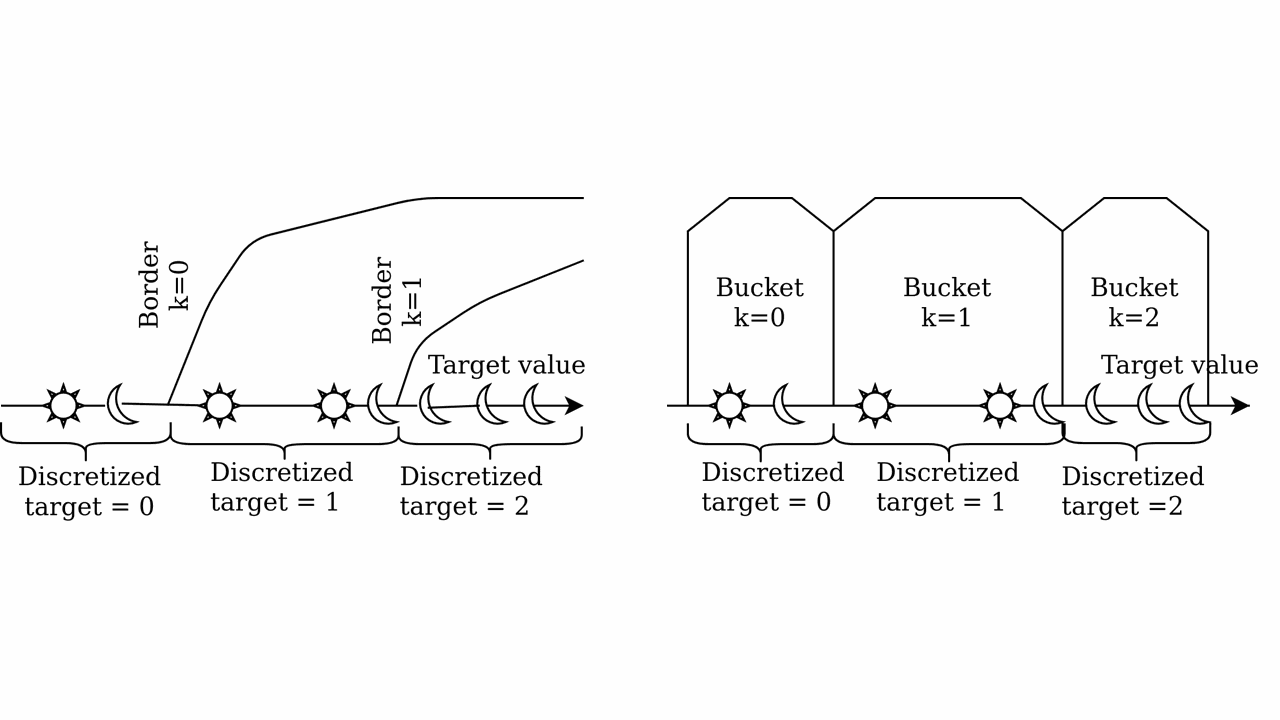
Borders
This method calculates a value called for each bucket (a range of values) in your categorical feature.
The formula for calculating it is:
$$\text{ctr} = \frac{\text{countInClass} + \text{prior}}{\text{totalCount} + 1}$$
You’ll notice they use “ctr” in the formula.
This comes from “click-through rate”, a metric used in online advertising corresponding to the number of clicks an ad receives divided by the number of times it’s shown.
I imagine they started by using this method for modeling advertising data inside Yandex, so they kept the terminology.
Here, countInClass is the number of times the target (Y) value exceeded the bucket’s value for instances with the current categorical feature value.
totalCount is the total number of instances that have a feature value matching the current one.
prior is a constant defined by the starting parameters.
Buckets
This method is similar to Borders, but it creates an extra bucket.
The formula for calculating ctr is the same, but countInClass is now the number of times the label value was equal to the bucket’s value (instead of exceeding it).
 Credits:
Credits: BinarizedTargetMeanValue
This method also calculates ctr using the same formula, but countInClass is now the ratio of the sum of the label value integers for this categorical feature to the maximum label value integer.
This is very similar to the mean (or likelihood) encoding method that you find on Kaggle.
Counter
This method doesn’t use the label value to transform the original categories, only the frequency of each value.
For the training dataset, curCount is the total number of instances with the current categorical feature value, and maxCount is the number of instances with the most frequent feature value.
The formula is:
$$\text{ctr} = \frac{\text{curCount} + \text{prior}}{\text{maxCount} + 1}$$
For the validation dataset, curCount can be calculated in two ways:
Full: the sum of the total number of instances in the training dataset and the validation dataset with the current categorical feature value.SkipTest: the total number of instances in the training dataset with the current categorical feature value.
SkipTest is the most realistic option as, in real life, you don’t have access to the full validation dataset at once.
maxCount is the number of instances with the most frequent feature value in the training dataset, the validation dataset, or both, depending on the calculation method.
CatBoost Regression Code Example
Now that we’ve covered the theory, let’s dive into some Python code.
We’ll use the Used Cars Prices dataset from Kaggle.
This dataset contains information extracted from ads in a Belarusian classifieds website.
The goal is to predict the price of a car based on its features.
First, let’s import the necessary libraries and load the data.
import pandas as pd
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
# Load the data
data = pd.read_csv(data_path)
data = pd.read_csv(data_path)
data['drive_unit'] = data['drive_unit'].fillna('missing')
data['segment'] = data['segment'].fillna('missing')
| make | model | priceUSD | year | condition | mileage(kilometers) | fuel_type | volume(cm3) | color | transmission | drive_unit | segment |
|---|---|---|---|---|---|---|---|---|---|---|---|
| mazda | 2 | 5500 | 2008 | with mileage | 162000 | petrol | 1500 | burgundy | mechanics | front-wheel drive | B |
| mazda | 2 | 5350 | 2009 | with mileage | 120000 | petrol | 1300 | black | mechanics | front-wheel drive | B |
| mazda | 2 | 7000 | 2009 | with mileage | 61000 | petrol | 1500 | silver | auto | front-wheel drive | B |
| mazda | 2 | 3300 | 2003 | with mileage | 265000 | diesel | 1400 | white | mechanics | front-wheel drive | B |
| mazda | 2 | 5200 | 2008 | with mileage | 97183 | diesel | 1400 | gray | mechanics | front-wheel drive | B |
CatBoost requires all values of categorical features to be strings, so I filled in the missing values with the string “missing”.
Next, let’s prepare our data for training.
We’ll separate our target variable (priceUSD) from the rest of the data, split it into training and test sets, and create a list with the names of the columns that contain categorical features.
X = data.drop('priceUSD', axis=1)
y = data['priceUSD']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
cat_features = ['make', 'model', 'condition', 'fuel_type', 'color', 'transmission', 'drive_unit', 'segment']
Now, we’re ready to train our model. Let’s use the CatBoostRegressor class with 100 estimators so it’s fast.
We’ll train and evaluate a model for each of the four encoding methods we covered earlier.
To keep things simple, the evaluation metric we’ll use is the root mean squared error (RMSE).
model_borders = CatBoostRegressor(cat_features=cat_features, simple_ctr='Borders', n_estimators=100, combinations_ctr='Borders')
model_borders.fit(X_train, y_train)
model_buckets = CatBoostRegressor(cat_features=cat_features, simple_ctr='Buckets', n_estimators=100, combinations_ctr='Buckets')
model_buckets.fit(X_train, y_train)
model_target = CatBoostRegressor(cat_features=cat_features, simple_ctr='BinarizedTargetMeanValue', n_estimators=100, combinations_ctr='BinarizedTargetMeanValue')
model_target.fit(X_train, y_train)
model_counter = CatBoostRegressor(cat_features=cat_features, simple_ctr='Counter', n_estimators=100, combinations_ctr='Counter')
model_counter.fit(X_train, y_train)
To tell CatBoost which features are categorical, we pass the list of column names to the cat_features parameter, and we set the simple_ctr and combinations_ctr parameters to the encoding method we want to use.
simple_ctr is the method used for single categorical features (the original ones we passed), but CatBoost also supports encoding combinations of categorical features (for example, the combination of make and model).
The encoding method for combinations of categorical features is set with the combinations_ctr parameter.
After training the models, we can evaluate them on the test set.
from sklearn.metrics import mean_squared_error
rmse_borders = mean_squared_error(y_test, model_borders.predict(X_test), squared=False)
rmse_buckets = mean_squared_error(y_test, model_buckets.predict(X_test), squared=False)
rmse_target = mean_squared_error(y_test, model_target.predict(X_test), squared=False)
rmse_counter = mean_squared_error(y_test, model_counter.predict(X_test), squared=False)
print(f'RMSE Borders: {rmse_borders}')
print(f'RMSE Buckets: {rmse_buckets}')
print(f'RMSE Target: {rmse_target}')
print(f'RMSE Counter: {rmse_counter}')
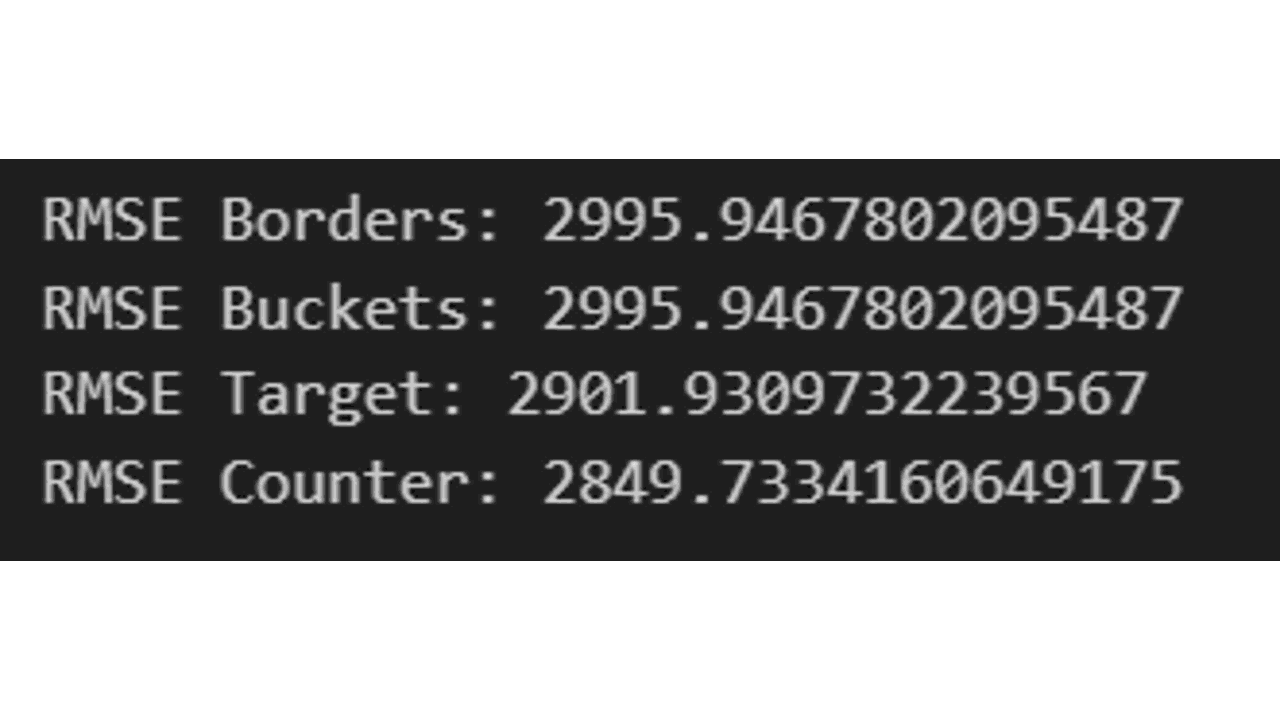
In this case, the BinarizedTargetMeanValue method performed the best.