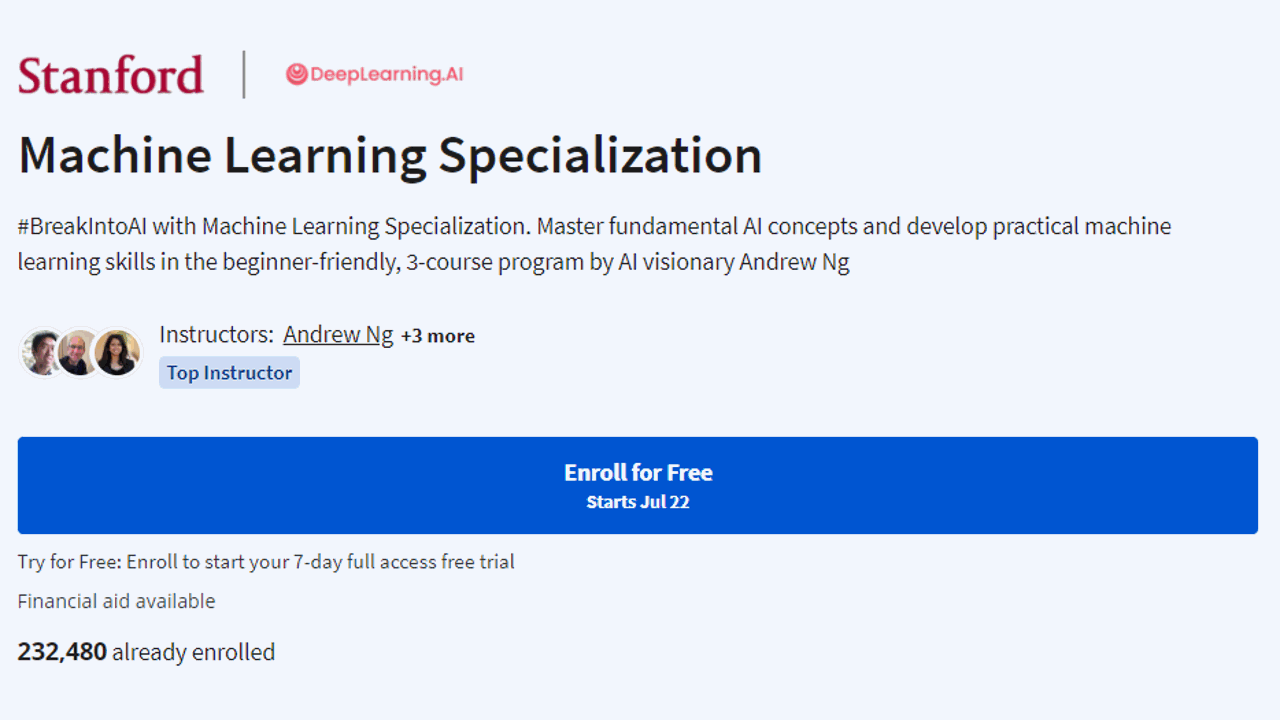
Is Coursera's Machine Learning Specialization Worth It In 2024? Review
Provider: DeepLearning.AI, Stanford University Teacher: Andrew Y. Ng Price: $49/month with a 7-day free trial Duration: Approx. 3 months if you study 9 hours per week Pre-requisites: basic Python programming skills, high school math Level: Beginner Certificate: Yes Stepping into the world of machine learning can be daunting, especially when you’re trying to decipher complex topics like regression models, learning algorithms and more. You could spend hours sifting through information online, but how can you know what’s reliable and what’s not?...