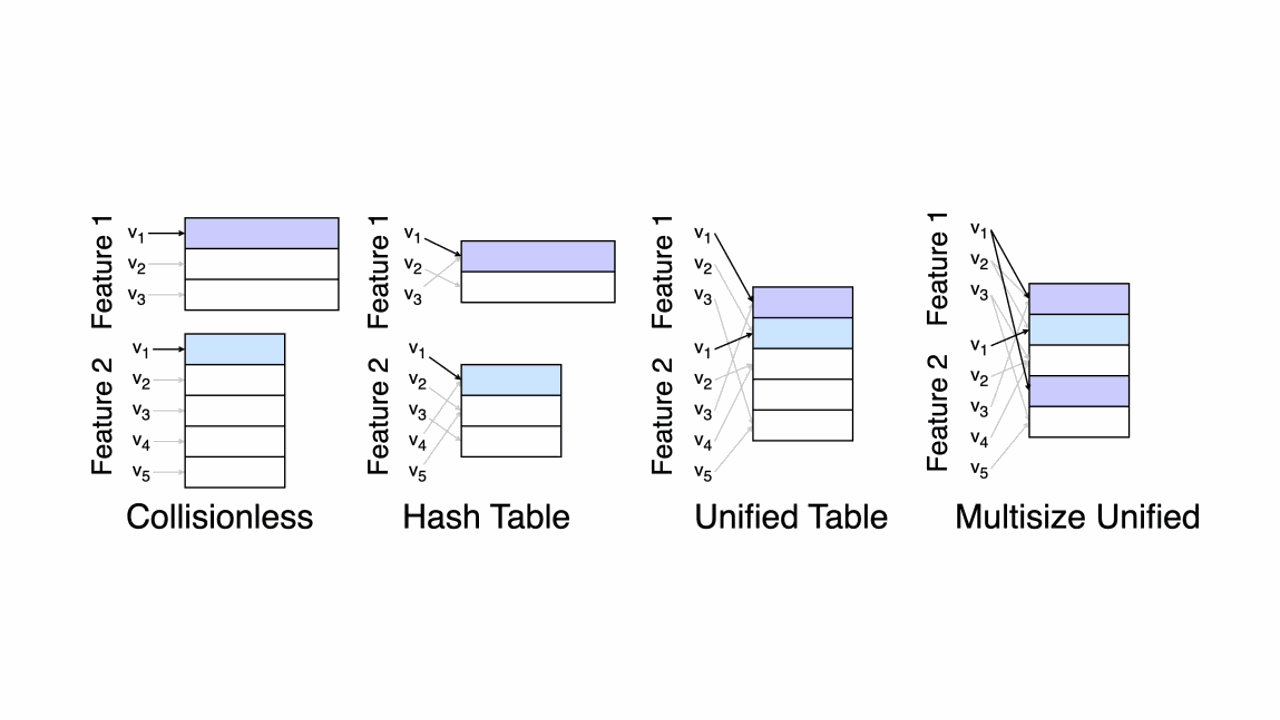
In machine learning, particularly in the field of recommendation systems and natural language processing, we often deal with categorical features.
These features can be anything from user IDs, product IDs, to words in a text.
One common practice to handle these categorical features is to represent them as embeddings, which are dense vector representations learned during the training process.
However, when dealing with web-scale machine learning systems, the number of unique categorical features can be extremely large, leading to a massive number of embeddings....