How To Use XGBoost For Regression In Python (Tutorial)
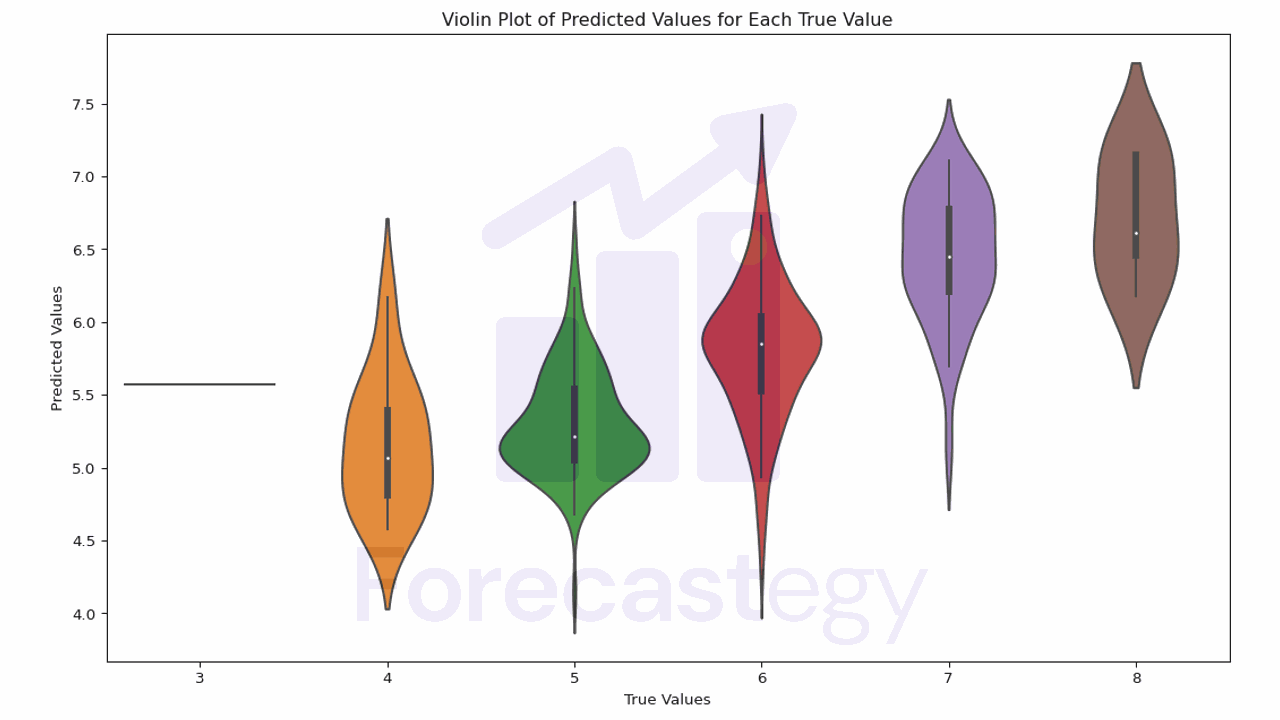
Are you struggling to get your regression models to perform well? Perhaps you’ve tried several algorithms, tuned your parameters, and even collected more data, but your model’s predictions are still off. You might be feeling frustrated and unsure of what to do next. Don’t worry, you’re not alone. Many machine learning practitioners face the same challenge. In this tutorial, I’m going to introduce you to XGBoost, a powerful machine learning algorithm that’s been winning competitions and helping companies make accurate predictions....