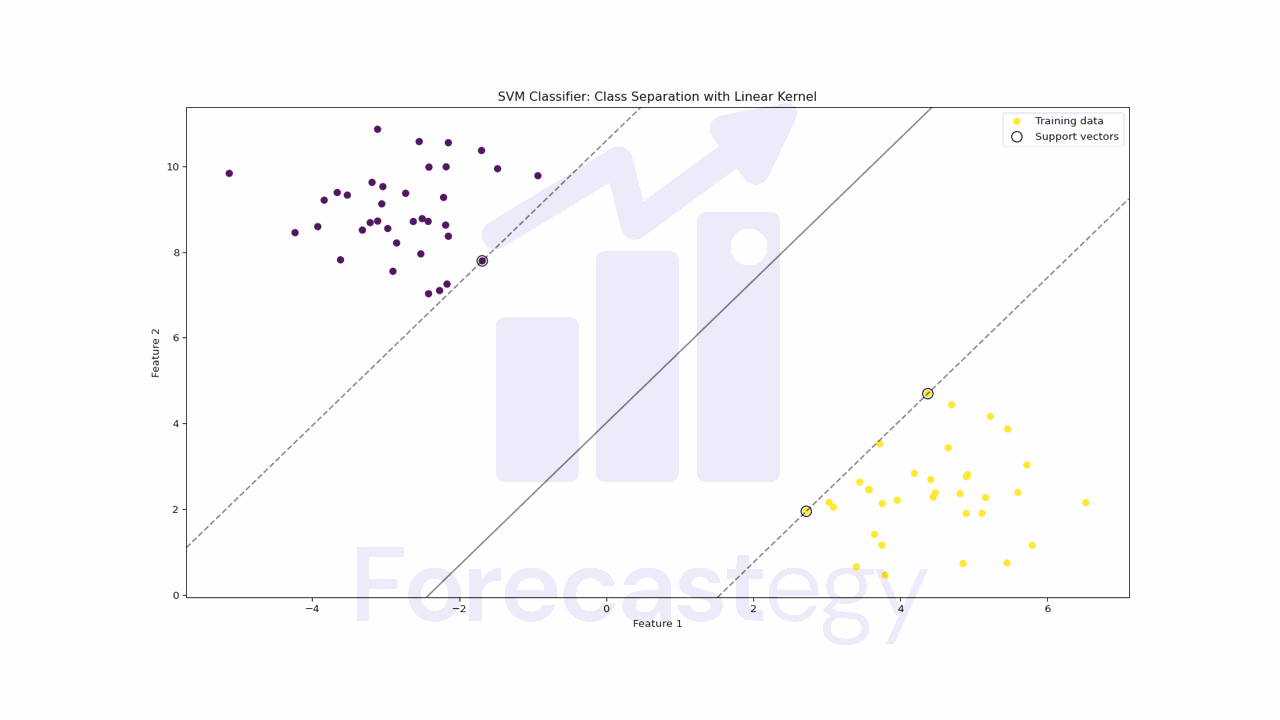
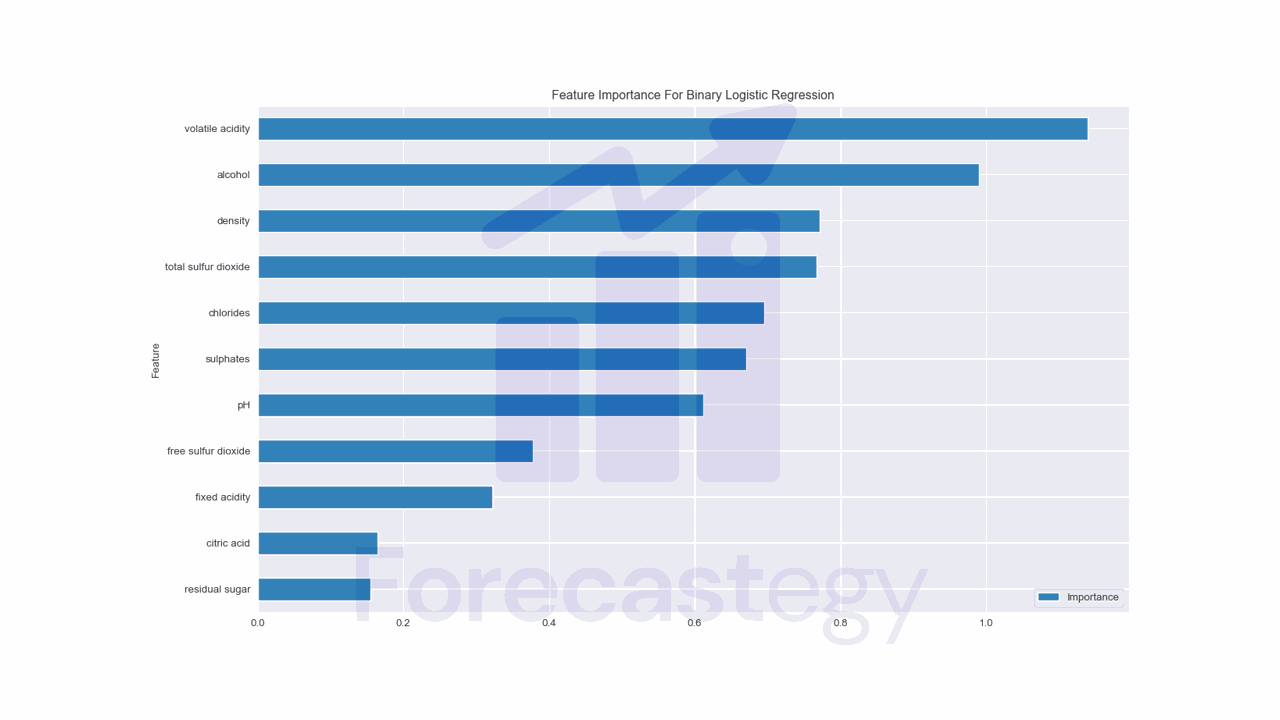
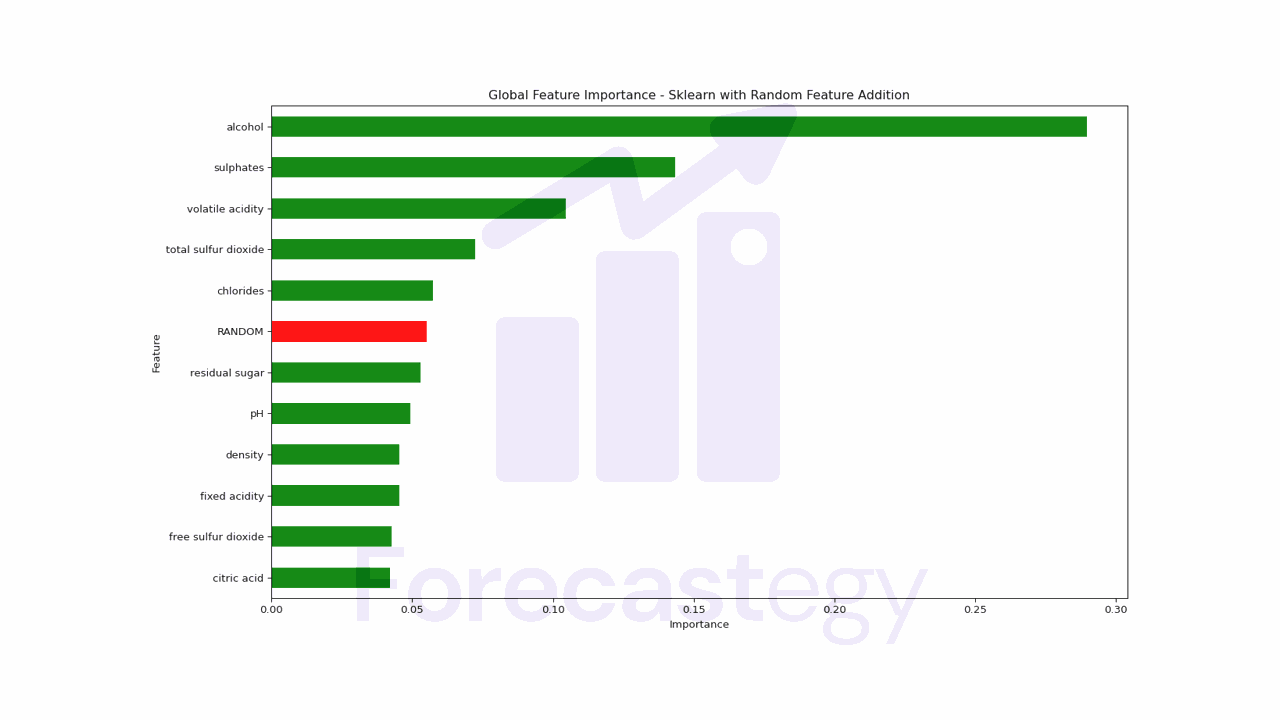
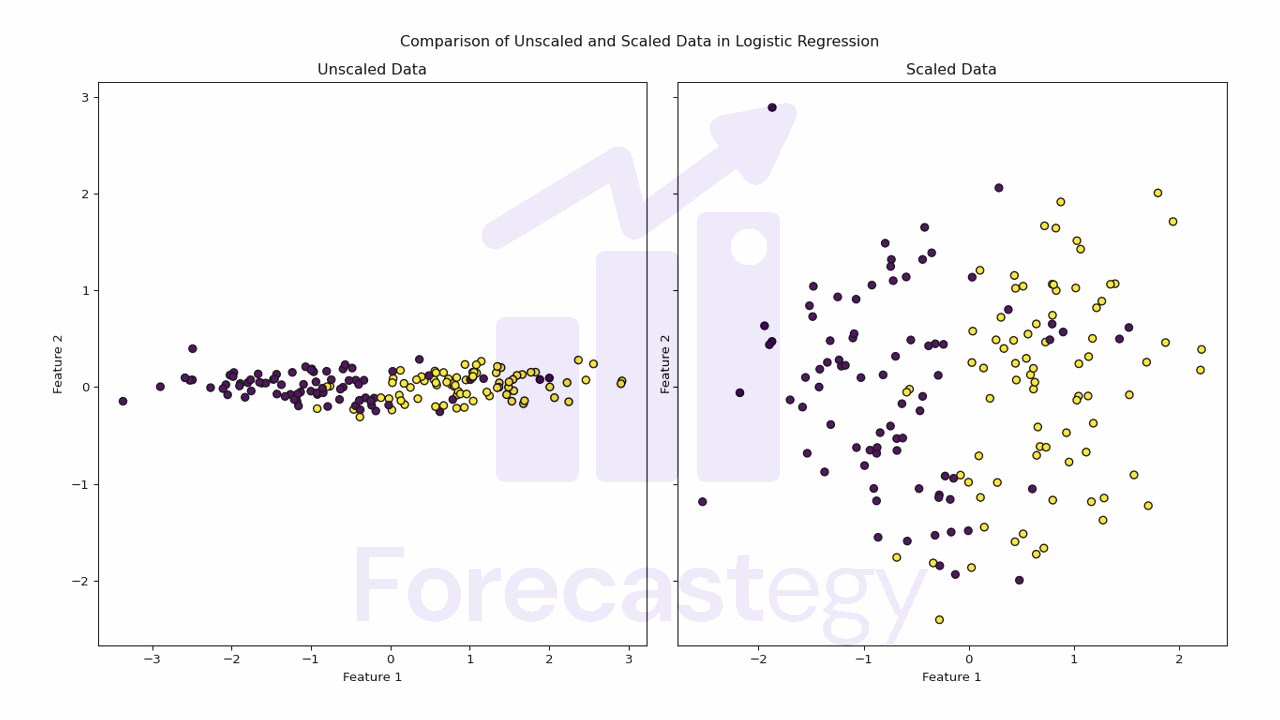
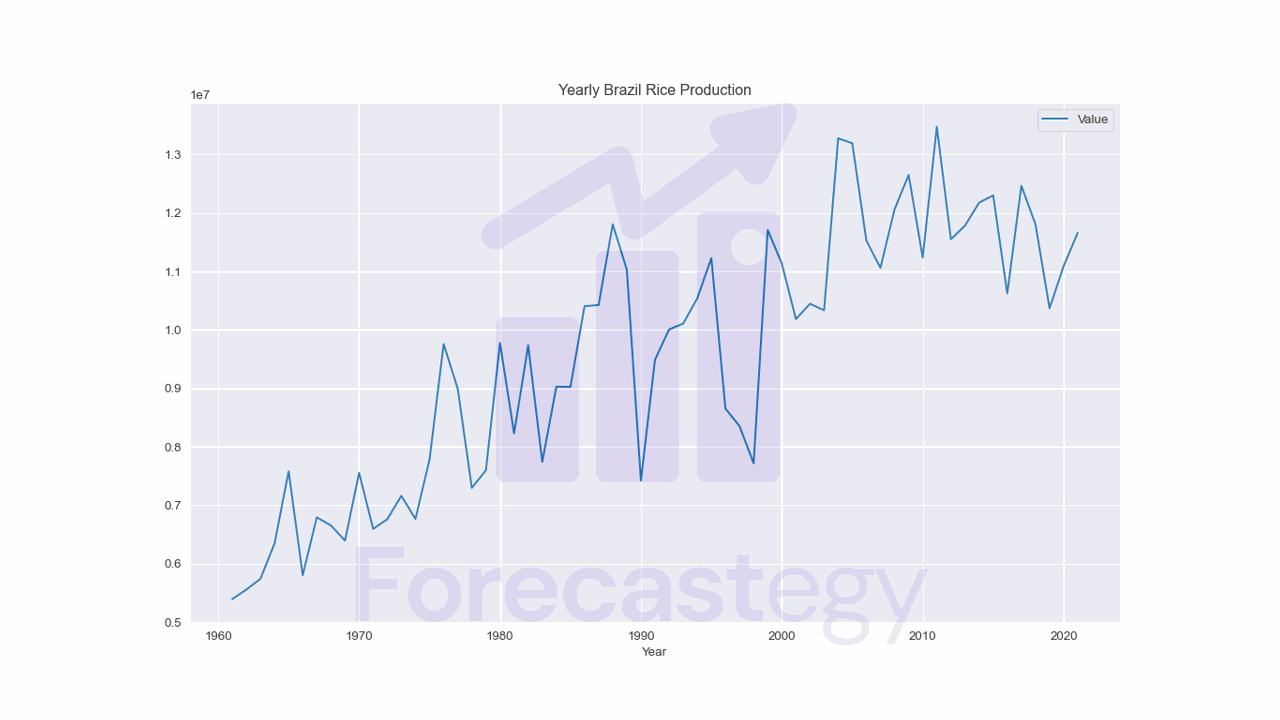
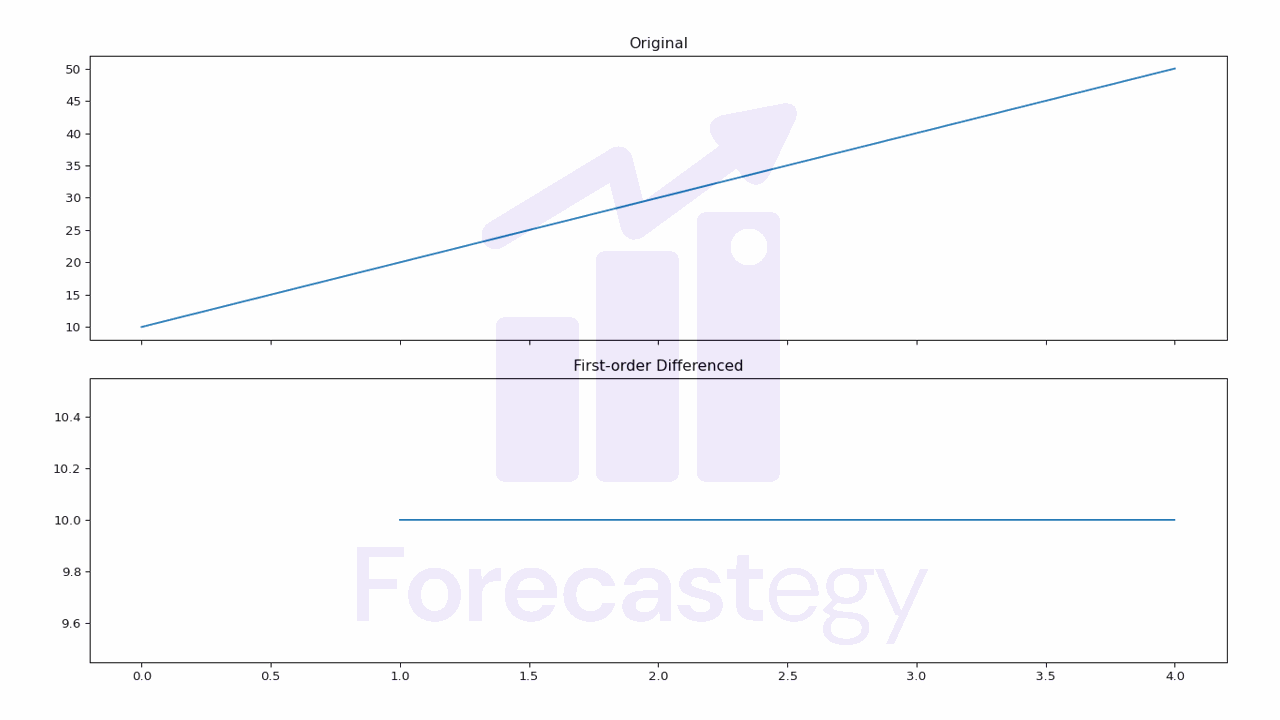
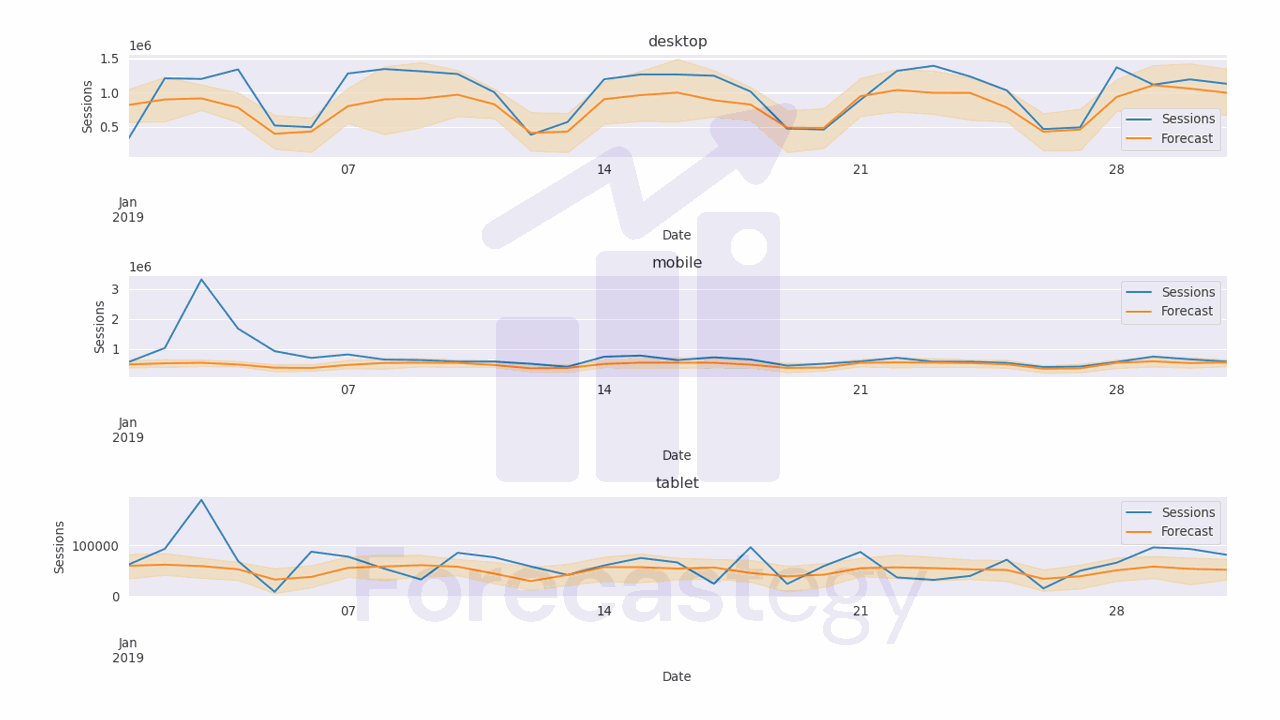
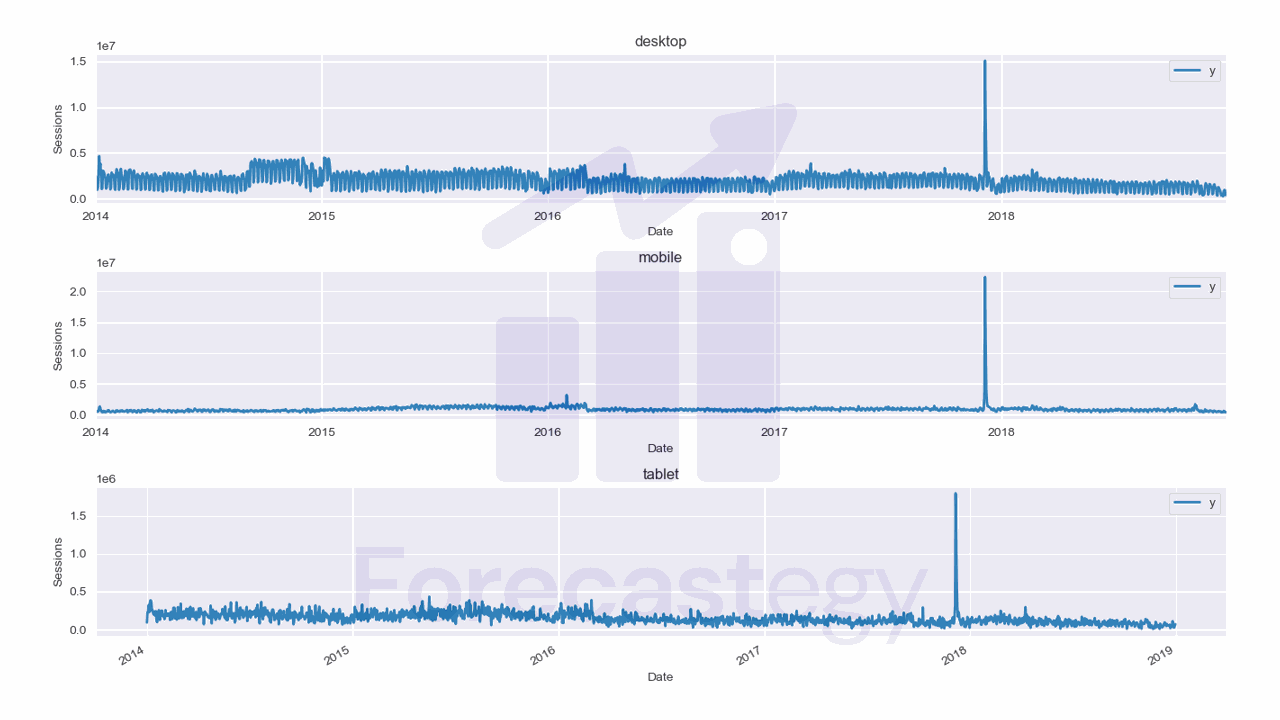
Do Neural Networks Need Feature Scaling Or Normalization?
In short, feature scaling or normalization is not strictly required for neural networks, but it is highly recommended. Scaling or normalizing the input features can be the difference between a neural network that converges in a few iterations and one that takes hundreds of iterations to converge or even fails to converge at all. The optimization process may become slower because the gradients in the direction of the larger-scale features will be significantly larger than the gradients in the direction of the smaller-scale features....