Andrew Ng On How To Read Machine Learning Papers
Learn how to read machine learning papers from Andrew Ng, one of the most influential researchers in the field of machine learning.
Learn how to read machine learning papers from Andrew Ng, one of the most influential researchers in the field of machine learning.

Gradient boosted decision trees (GBDTs) are the current state of the art on tabular data. They are used in many Kaggle competitions and are the go-to model for many data scientists, as they tend to get better performance than neural networks while being easier and faster to train. Neural networks, on the other hand, are the state of the art in many other tasks, such as image classification, natural language processing, and speech recognition....
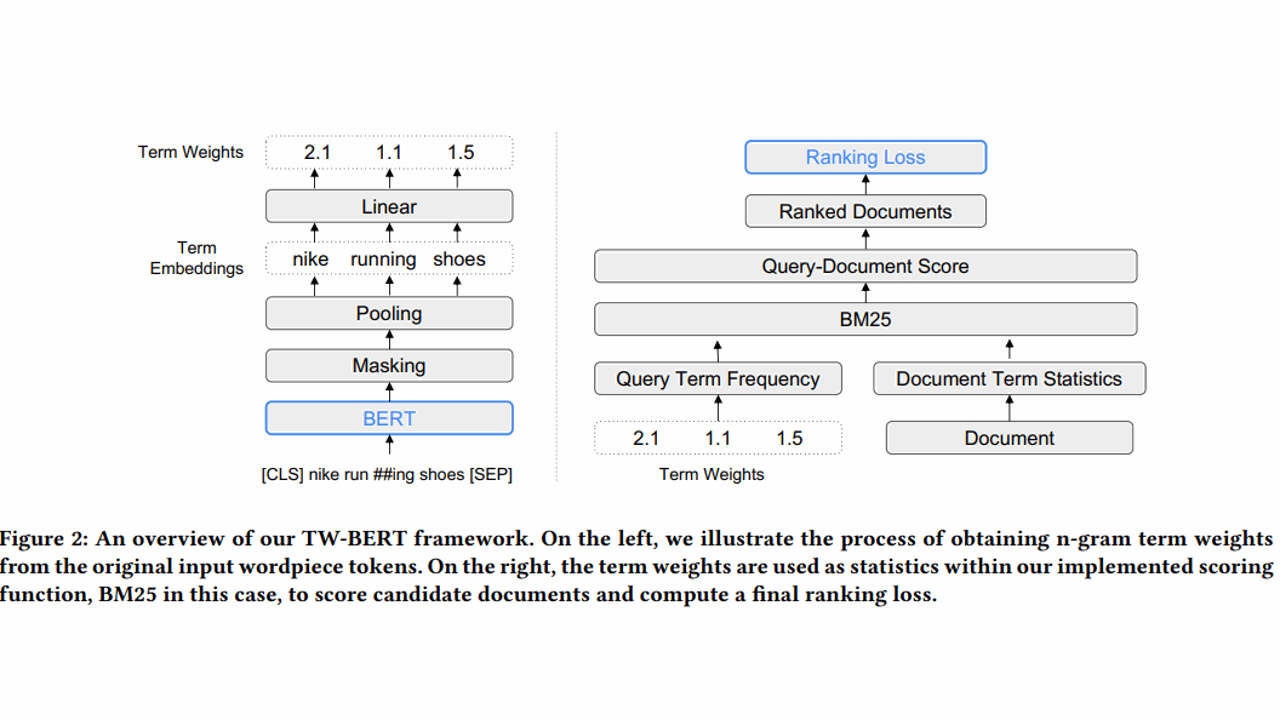
Information retrieval (IR) systems are crucial for a wide range of applications, from web search engines to personal digital assistants. However, traditional IR systems can struggle with accurately understanding and ranking the relevance of documents based on user queries. They typically rely on simple term-matching methods, known as sparse retrieval methods, that may not fully capture the semantic meanings of the terms in the queries. While these methods are computationally efficient and easy to scale, they treat each term independently and fail to capture the contextual relationships between them....
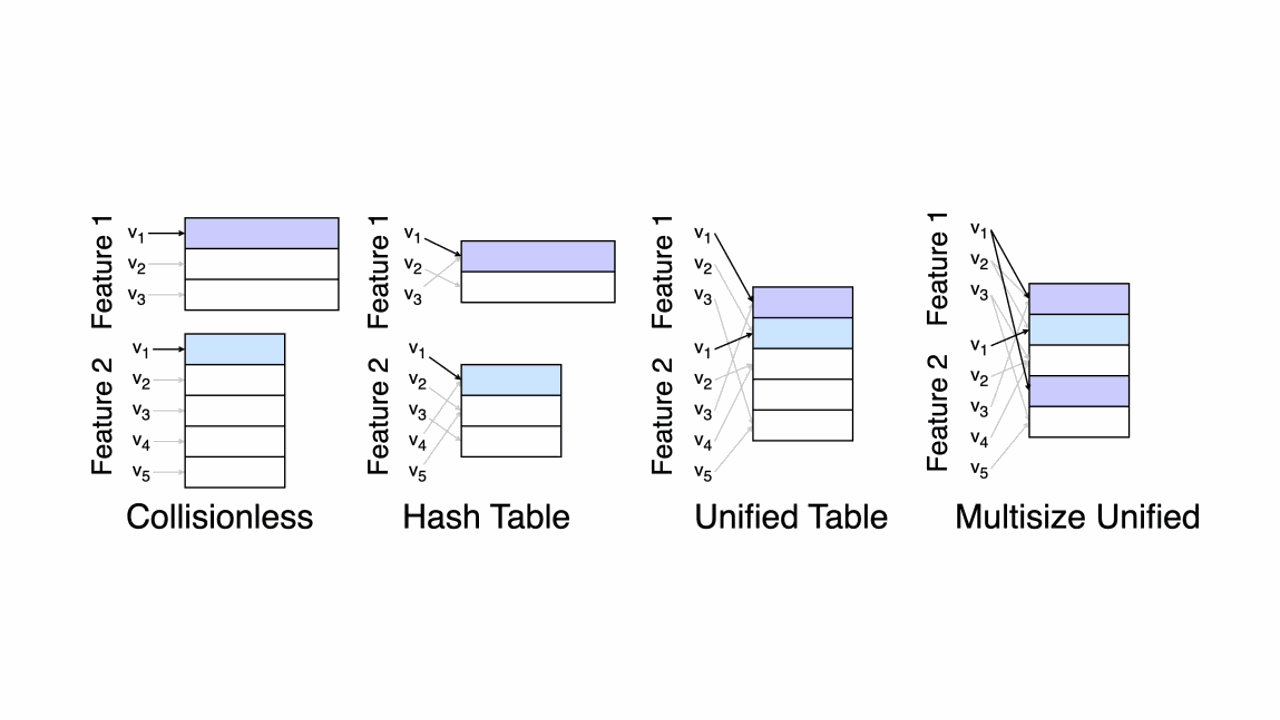
In machine learning, particularly in the field of recommendation systems and natural language processing, we often deal with categorical features. These features can be anything from user IDs, product IDs, to words in a text. One common practice to handle these categorical features is to represent them as embeddings, which are dense vector representations learned during the training process. However, when dealing with web-scale machine learning systems, the number of unique categorical features can be extremely large, leading to a massive number of embeddings....

Are you looking to train a Random Forest using XGBoost for classification or regression tasks but aren’t sure where to start? In this tutorial, I will first briefly explain the mechanisms behind XGBoost and Random Forest and highlight their differences. Then, I’ll guide you through a step-by-step process of training an XGBoost Random Forest for both classification and regression tasks using a real-world dataset. By the end of this tutorial, you’ll be well-equipped to tackle your own projects with confidence and expertise....

This tutorial is your roadmap to training a LightGBM model for ranking tasks in Python. You’ll learn how to install LightGBM in your Python environment, prepare your data correctly, and train a model using LightGBM’s Ranker. I’ll also cover how to evaluate your model’s performance using the industry-standard Normalized Discounted Cumulative Gain (NDCG) metric. By the end, you’ll have a solid understanding of LTR with LightGBM and be ready to tackle real-world ranking problems....

Looking to use LightGBM for multiclass classification in Python but unsure of how to proceed? This tutorial is designed to get you up to speed. I’ll guide you through each step, from data preparation to model building, training, and evaluation. By the end of this tutorial, you will be ready to apply these steps to your own projects. So, let’s dive right in! Installing LightGBM in Python Before we dive into the main content of this tutorial, let’s first ensure that you have the LightGBM library installed in your Python environment....

Are you trying to create a regression model using the LightGBM library in Python but finding it challenging? Perhaps you’re unsure about installing the library, setting up the model, preparing the data, or evaluating your model’s performance. You’re in the right place. This tutorial will guide you through each of these steps. We’ll install LightGBM, prepare a dataset, train a model, make predictions, and evaluate the results. By the end, you’ll have a functional LightGBM regression model and a solid understanding of the process....

Want to use LightGBM for a binary classification task but feel stuck? In this tutorial, you are going to see an example of how to do it in Python step-by-step. I’ll also explain how to handle class imbalance, a common issue in binary classification tasks. What Is LightGBM? LightGBM, which stands for “Light Gradient Boosting Machine,” is an open-source, distributed, high-performance gradient boosting framework developed by Microsoft. It is designed for efficient and scalable training of large datasets and is particularly well-suited for problems involving large numbers of features or high-dimensional data....

As a Python user aiming to predict a continuous target variable from a dataset with both numerical and categorical features, you’ve made a great choice in considering CatBoost. This high-performance machine learning algorithm is particularly known for its ability to handle categorical variables effectively. In this tutorial, I’ll guide you step-by-step on how to use CatBoost for regression tasks. We’ll start from preparing your data, training the CatBoost model, and finally evaluating its performance....

Are you looking to tackle a multiclass classification problem using Python and stumbled upon CatBoost? Or perhaps you’ve heard about CatBoost’s impressive handling of categorical data and now you’re curious to see it in action with multiclass classification. Either way, you’ve come to the right place! In this tutorial, we’re going to explore how to use CatBoost, a powerful machine learning library, to conquer multiclass classification problems. I’ll start by giving you a quick primer on CatBoost and why it’s an excellent choice for multiclass classification....

Have you ever found yourself puzzled by the different options for categorical encoding in CatBoost? With so many methods available, it can be quite a challenge to figure out which one is the best fit for your project. In this tutorial, I will demystify the various encoding options. By the end of this guide, you’ll be well-equipped to make an informed decision and handle categorical features in CatBoost like a pro!...

Many people find the initial setup of CatBoost a bit daunting. Perhaps you’ve heard about its ability to work with categorical features without any preprocessing, but you’re feeling stuck on how to take the first step. In this step-by-step tutorial, I’m going to simplify things for you. After all, it’s just another gradient boosting library to have in your toolbox. We’ll walk you through the process of installing CatBoost, loading your data, and setting up a CatBoost classifier....
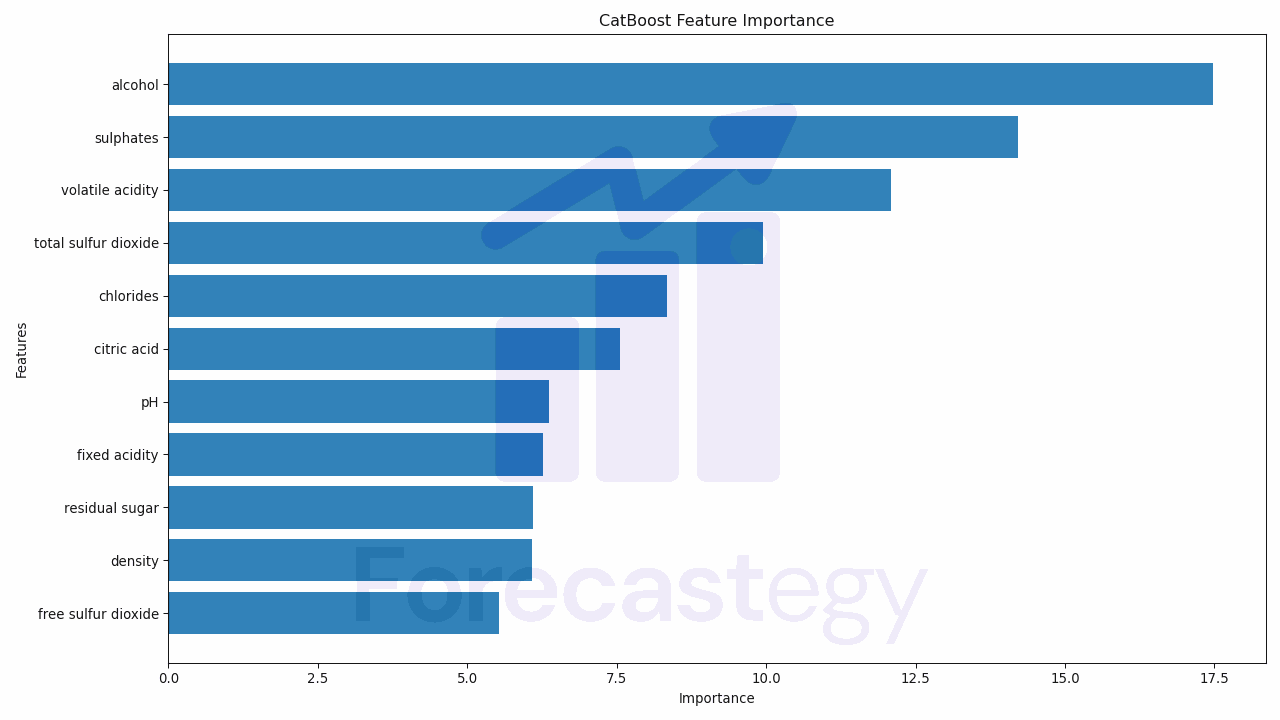
If you’ve ever used CatBoost for machine learning, you know it’s a powerful tool. But did you know it has several ways of calculating feature importances? Understanding how these methods work can help you get more out of your models. However, these methods can get a bit complex, and it’s not always clear when to use each one. It’s like trying to choose the right tool from a toolbox when you don’t know what each tool does....
So, you’ve heard about the power of XGBoost for Learning to Rank (LTR) tasks and want to harness it, right? You couldn’t have landed in a better place! XGBoost is a go-to tool for many LTR applications, from predicting click-through rates and powering search engines to enhancing recommender systems. I can vouch for its effectiveness, having used it to build models for ranking freelancers on Upwork. In this tutorial, we’ll unlock the potential of XGBoost for your LTR tasks....

In machine learning, we often come across datasets where the number of observations in one class significantly outweighs the other. This is known as imbalanced data. For instance, in a dataset of credit card transactions, the number of fraudulent transactions (positive class) is usually much smaller than the number of legitimate transactions (negative class). This is also an example of a binary classification task, which is a common type of machine learning problem....

Multi-output regression is a machine learning task where we need to predict multiple outputs from a single set of inputs. Imagine you’re a financial analyst at an investment firm. Your job is to predict the future performance of various stocks to guide investment decisions. For each stock, you want to predict several outputs such as the expected return, the volatility (risk), and the correlation with other stocks or market indices....
Multiclass classification is a machine learning task where the output can belong to more than two classes. In other words, it can sort data into multiple categories. For example, a piece of fruit can be classified as an ‘apple’, ‘banana’, or ‘cherry’. Or, a car can be classified as ‘sedan’, ‘SUV’, or ’truck’. Just like binary classification, we can use a variety of algorithms to classify the data points into these multiple categories....

Binary classification is a type of machine learning task where the output is a binary outcome, i.e., it belongs to one out of two classes. For example, an email can be classified as either ‘spam’ or ’not spam’, or a tumor can be ‘malignant’ or ‘benign’. When you have more than two classes, it’s called multiclass classification. We can use various algorithms to classify the data points. These algorithms include logistic regression, decision trees, random forest, support vector machines, and gradient boosting algorithms like XGBoost....

You’ve spent countless hours researching, tweaking, and training the perfect XGBoost model. Your model is performing exceptionally well and you’re ready to celebrate. But wait, now you need to deploy it, and suddenly, you’re faced with a problem. How do you save your model for future use? Don’t worry, there’s a simple solution to this! In this article, I will walk you through how to save and load your XGBoost models....